LLM推理服务论文
记录一些LLM推理优化相关的论文
FlashAttention
PageAttention
RadixAttention
RingAttention
RAGCache [Arxiv24]
Cache-Craft [SIGMOD25]
CacheBlend [EuroSys25]
Superposition [ICLR24]
AquaPipe [SIGMOD25]
AquaPipe: A Quality-Aware Pipeline for Knowledge Retrieval and Large Language Models [paper]
Similarity-based Retrieval
RetrievalAttention [Arxiv24]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval [paper] [code]
RetroInfer [Arxiv25]
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference [paper] [[code] [author]
PQCache [SIGMOD25]
PQCache: Product Quantization-based KVCache for Long Context LLM Inference [paper] [code]
PQCache解决的LLM在long context下的推理效率问题。
长上下文推理对显存需求带来了挑战,如何在有限的显存空间实现高效的推理,同时保存高的输出质量,是一个被广泛关注的问题。
一个符合直觉的方法:selective attention,通过选择部分token进行注意力计算,显著降低了对内存和计算的需求。
现有selective attention方法可以分为:KV Cache dropping (Scissorhands, StreamingLLM [ICLR24], H2O [NIPS23]),KV Cache offloading (InfLLM [arxiv24] SparQAttention) 两类。
如下图所示,PQCache发现selective attention的执行和传统信息检索的Product Quantization的过程很像。
在LLM的注意力计算过程中,向量Q和所有的K进行相似度计算,然后经过softmax并与V加权求和得到输出X。
Q和K的相似度计算和信息检索中根据用户问题检索相似的top-k个向量的过程基本一致。
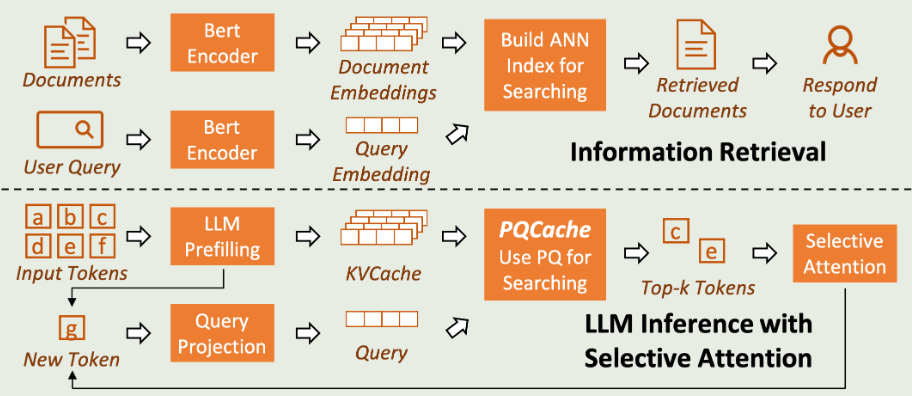
本文选择了开销比较低的Product Quantization来管理KV Cache。
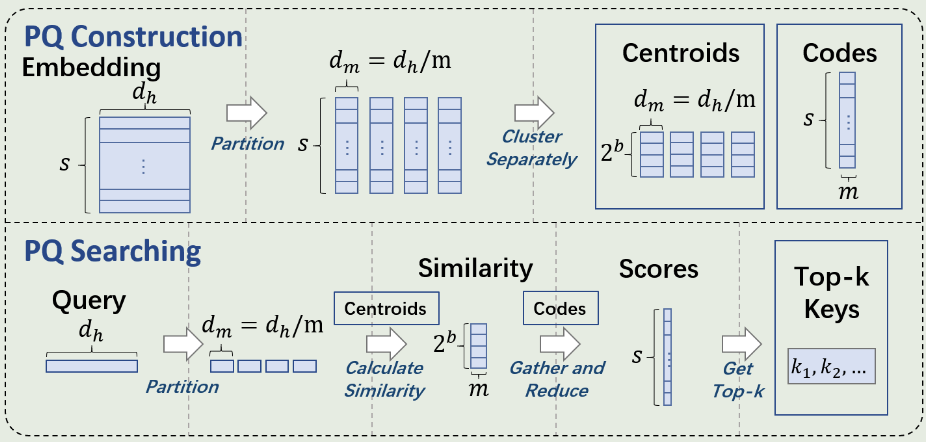
PQ的索引构建和搜索过程如下图所示。
PQ Construction:
- 将每个KV Cache向量划分为m个子向量。
- 对所有KV Cache的每个子向量进行聚类,生成$2^b$个质心。
- 原来KV Cache向量对应的m个子向量编码为距离最近的质心id。
PQ Searching:
- 查询Q向量同样被划分为M个子向量。
- 每个子向量和对应的空间中$2^b$个向量计算相似度。
- 根据相似度计算原始向量与Q的相似性得分,选取TopK得分的向量。
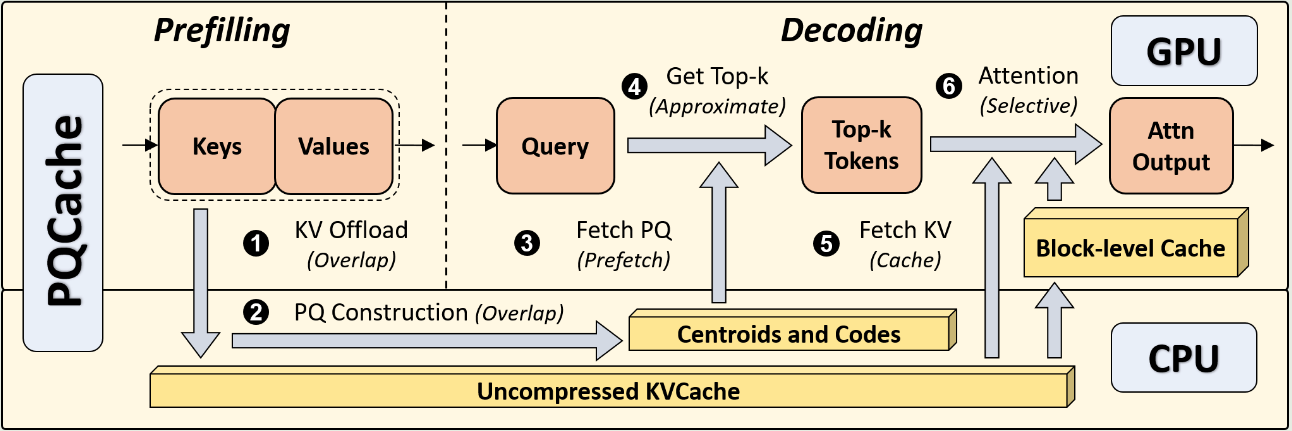
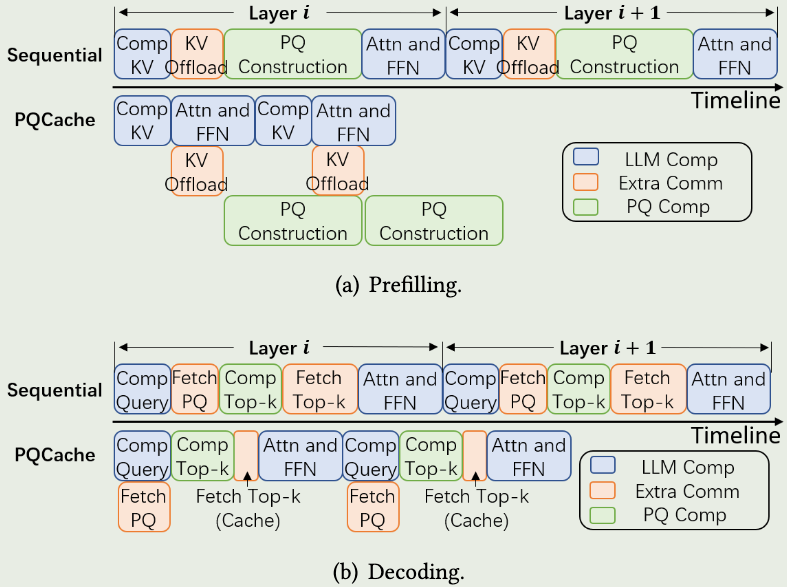
PQCache的整体执行流程如下图所示:
- 在Prefilling阶段,正常计算得到每个输入token的KV Cache,并异步的卸载到CPU。
- CPU收到KV Cache之后,构建PQ用于后续检索。
- 在Decoding阶段,加载Centroids和PQ Codes,并计算TopK K向量。
- 根据计算的TopK向量,加载对应KV向量,并在GPU执行注意力计算。
在实现中,PQCache的KV Cache包含三种:initial tokens,middle tokens,and local tokens.
StreamingLLM中发现attention sink的现象,即initial tokens受到更多的注意力关注,对模型的回答质量有很大的影响。
local tokens表示最近计算的token。middle tokens表示历史KV Cache保存在CPU中。
PQCache将initial和local tokens保存在GPU,并维护一个窗口,超过窗口的local token被卸载到CPU。
Apt-Serve [SIGMOD25]
Apt-Serve: Adaptive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving [code] [paper]
Scheduling
Parrot [OSDI24]
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable. [pdf] [code] [author]
Parrot这篇论文的主要贡献是提出了一个全新的推理workload:LLM Applications。
LLM Application是使用LLM来完成特定的任务(摘要,搜索,代码助手等),在一个应用中通常包含多个LLM请求。
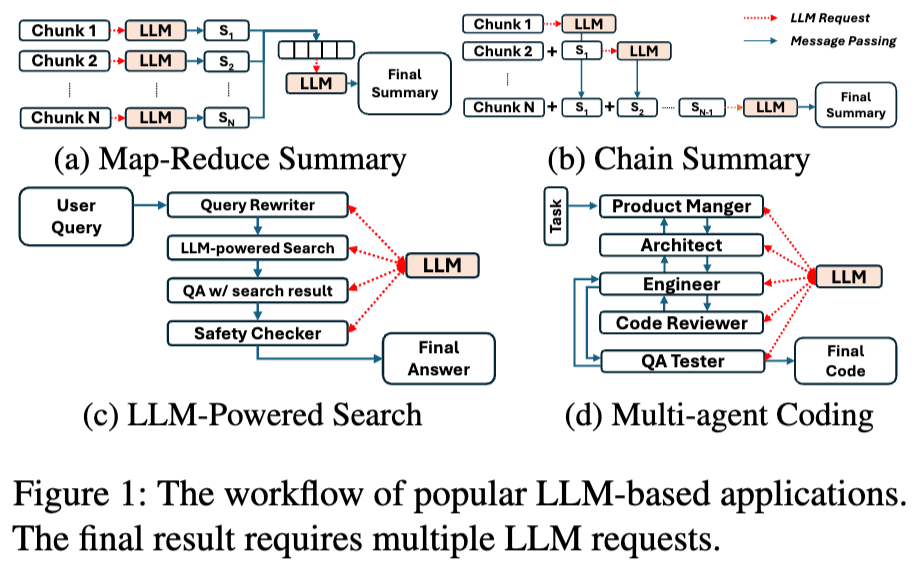
以往推理优化系统是request-centric,即对用户的应用是透明的,“一视同仁”的处理用户的请求,缺少application-level的信息。
在LLM Application中,请求具有以下特点:
- 多个连续的LLM请求可能存在依赖关系。
- 即使在单个应用中,LLM请求可能具有不同的调度偏好。
- LLM的请求之前存在大量的相似性。
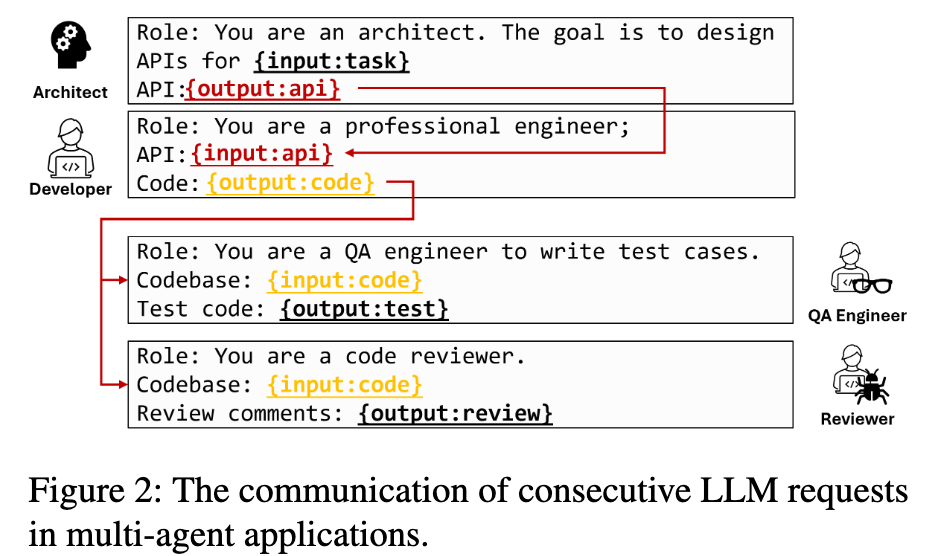
由于缺少application-level的信息,现有的推理优化主要有两个问题:
- 网络通信开销。
- 任务调度等待开销。
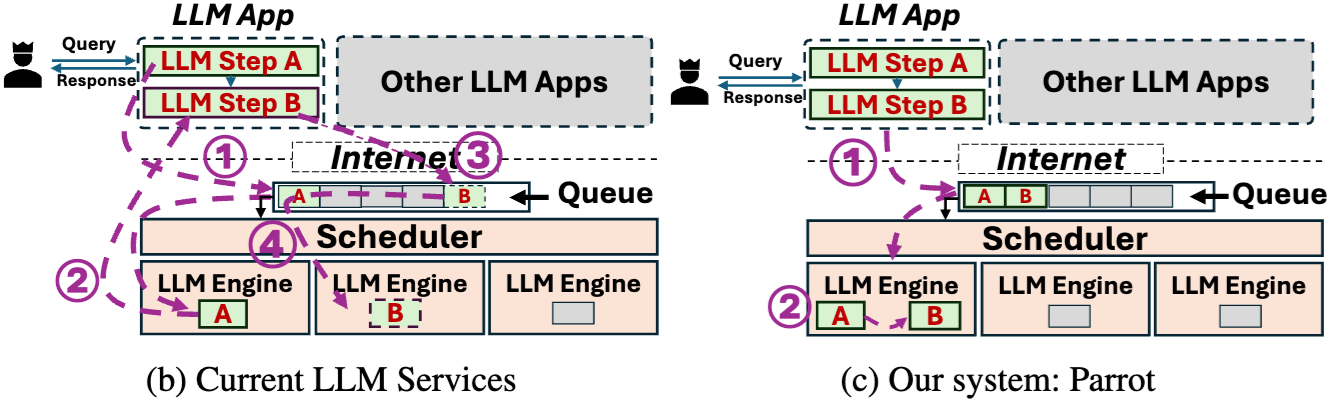
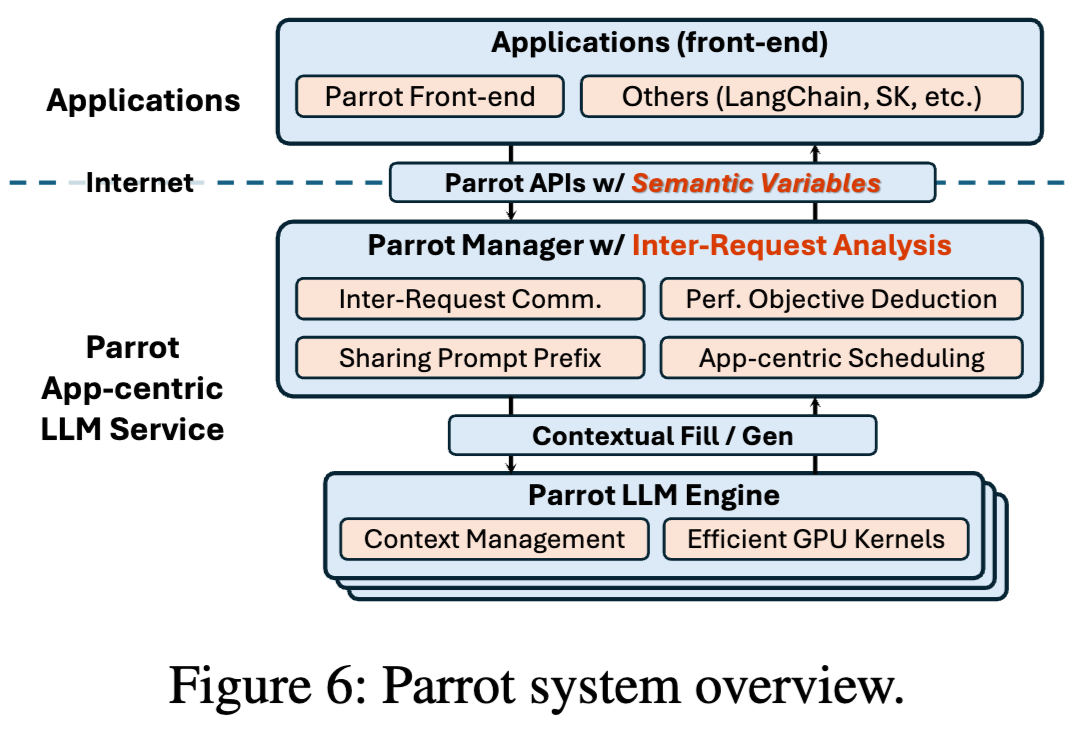
Parrot设计了一个Semantic Variables的编程抽象,用来将用户的执行逻辑暴露给推理服务端。
基于这个Semantic Variables可以获取到应用内的LLM请求的调用依赖关系,进而做一些系统上的优化,包括DAG-based analysis,Performance Objective Deduction,Application-Centric Scheduling等。

Preble [ICLR25]
Preble: Efficient Distributed Prompt Scheduling for LLM Serving [paper] [code]
现有推理系统的目标是充分利用GPU的计算资源,在调度请求时忽略了promt的共享前缀,因此存在冗余的计算开销。此外,简单的将共享前缀请求分配到同一个实例,会造成负载的不均衡。
Preble针对分布式推理场景,提出了一个prompt-aware的请求调度方法。
Preble首先对LLM workload进行分析,有以下4个观察:
- Prompt 的长度远大于 Output:在真实 workload 中,Prompt 比 Output 长 4–2494 倍。
- Prompt 高度共享:85%–97% 的前缀可被复用。
- 共享序列频繁复用:常见前缀平均被 8.6–126 个请求使用,但不同 workload 差异明显。
- 请求模式极端不均:请求到达间隔从微秒到数百秒不等,系统需同时处理高并发和稀疏请求。
Preble包含以下设计:
- globa-local两层的调度机制,global调度将请求分配到对应的实例,local调度负责在实例内部迭代的调度请求。
- global调度策略如下:
- 如果缓存命中的token数量大于未命中,将请求分配到具有最长共享前缀的实例。如果有多个实例满足,则优先分配到负载最少的实例。
- 如果缓存命中token数量小于未命中,将请求分配到最小cost的实例,cost计算逻辑如下:
- 实例的负载,计算一定时间窗口内,所有请求的计算负载,包括prefill和decode,根据长度计算。
- 驱逐开销,插入新请求可能要驱逐一些节点,计算被驱逐节点的开销。
- 请求的prefill开销,prefill未命中token的计算开销。
- 为了缓解实例之间的负载不均衡问题,preble采用了负载调整方法:
- 如果实例之间的负载超过一定阈值,负载大的请求调度到负载小的实例上。
- 将频繁复用的前缀复制到多个机器,减轻单个实例的过载问题。
- global根据prefill和decode的负载,优先将请求分配到decode重的实例。
- 为了保证调度的公平,local调度根据cache token的数量对请求划分多个组,每次按比例的从每个组选择请求,cache命中多的组多选。

TaiChi [Arxiv25]
Prefill-Decode Aggregation or Disaggregation? Unifying Both for Goodput-Optimized LLM Serving [paper]
本文对PD-aggregation和PD-disaggregation进行了详细的总结对比,并提出了一个PD-aggregation和PD-disaggregationd的混合推理方法,以实现LLM推理 Goodput的最大化。
Motivation
PD-aggregation和PD-disaggregation适应不同的SLO,无法适用于TTFT和TPOT均衡的SLO。
- PD-aggregation适合“TTFT严格,TPOT宽松”的SLO。在PD-aggregation中,所有实例参与prefill,因此可以实现较低的TTFT表现;但是由于prefill和decode相互干扰导致TPOT较高。
- PD-disaggregation适合“TPOP严格,TTFT宽松”的SLO。在PD-disaggregation中,prefill和decode有不同的实例单独服务,decode不再受prefill的影响,因此TPOT较低;但是由于只有部分实例参与prefill,因此TTFT较高;
Observation
- PD-aggregation的高TPOT来自prefill的干扰:compute-bound linear operations(矩阵乘),其中TPOT与干扰的密度呈线性关系。(干扰密度=prefill tokens / output tokens)。在PD-aggregation中,chunk size是个关键参数,减少chunk size可以减轻prefill和decode的干扰,从而降低TPOT;但同时增加了prefill迭代的次数从而增加了TTFT。(section 2.3)
- PD-disaggregation的高TTFT来自于请求的等待开销(同时包括prefill和decode的等待开销)。当调整PD的实例比例,TTFT随着P的下降后上升。这是因为增加P实例可以同时处理更多的prefiil任务,但随着D数量的减少,使得decode任务的排队时间大大上升,进而导致整体的TTFT延迟升高。(section 2.3.2)
- 通过调度资源可以实现TTFT和TPOT延迟的转移,例如,在PD-aggregation中,增加chunk size可以将TTFT的延迟转移到TPOT上,因为增加chunk size可以为prefill提供更多的空间,代价是增加了TPOT的延迟。同样,在PD-disaggregation中,增加更多的decode实例,可以将TPOT的延迟转移到TTFT上。(section 2.4)
Challenge
现有LLM推理服务在PD-aggregation和PD-disagregation中二选一,虽然可以通过增加chunk size和调整PD实例数量来实现延迟转移,但是不够灵活,不支持request-level 延迟转移。(2.5 Challenge 1)
request-level的TPOT降级同时受到批处理和输出token长度不确定的影响。增加chunk size虽然可以将TTFT延迟转移到TPOT,但是可能导致同一批次一些decode请求的TPOT超过SLO;短输出长度的请求更容易受到PD干扰(output tokens是干扰密度的分母,对干扰更加敏感)。(2.5 Challenge 2)
request-level的TTFT的降级需求不直接,需要同时考虑执行时间和排队时间。prefill的长度比较分散(2k-16k不等),对于短请求的TTFT容忍度更高可以被优先降级。然而如果请求排队时间过长,那么他降级的空间就会大幅减少。(2.5 Challenge 3)
Design
- TaiChi将实例划分为两部分:P-heavy(大chunk size)和D-heavy(小chunk size),每个实例都有一个控制chunk size的slider($S_P$, $S_D$),通过调节slider可以动态的切换到PD-aggregation($S_P$=$S_D$=chunk size)和PD-disaggregation($S_D$排除prefill,$S_P$=maxinum)。其外,TaiChi通过来调节P-heavy和D-heavy的比例($R_{PD}$)以适应不同的SLO。
- 提出Flowing Decode Scheduling来实现request-level TPOT降级(Challenge 2),核心思想是在P-heavy和D-heavy之间动态的迁移需要降级的请求。首先,Decode任务优先分配到D-heavy实例,这样可以防止短输出的请求放到P-heavy超过SLO。当内存占用超过一定阈值,选择当前输出长度最长的请求进行降级(长度越长对TPOT相对更加不敏感)。
- TPOT-aware Decode Backflow,TaiChi会监控从D-heavy迁移到P-heavy的请求,如果他们的TPOT超过一定的阈值($\alpha \times$ SLO),则将这些请求重新迁移到D-heavy。Backflow这个方法是一个保障策略,如果backflow发生的比较频繁,说明当前的D-heavy过载,最好的方法通过调整$R_{PD}$来增加D-heavy的实例。
- Length-aware Prefill Scheduling,核心思想是优先将短提示词调度到D-heavy,使得P-heavy具有更多的资源处理SLO更加严格的长提示词。

Agent
Ayo [ASPLOS25]
Towards End-to-End Optimization of LLM-based Applications with Ayo [paper] [code] [author]
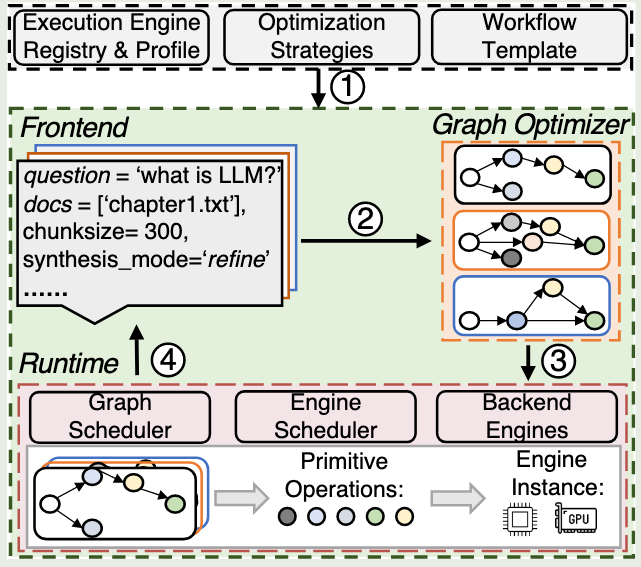
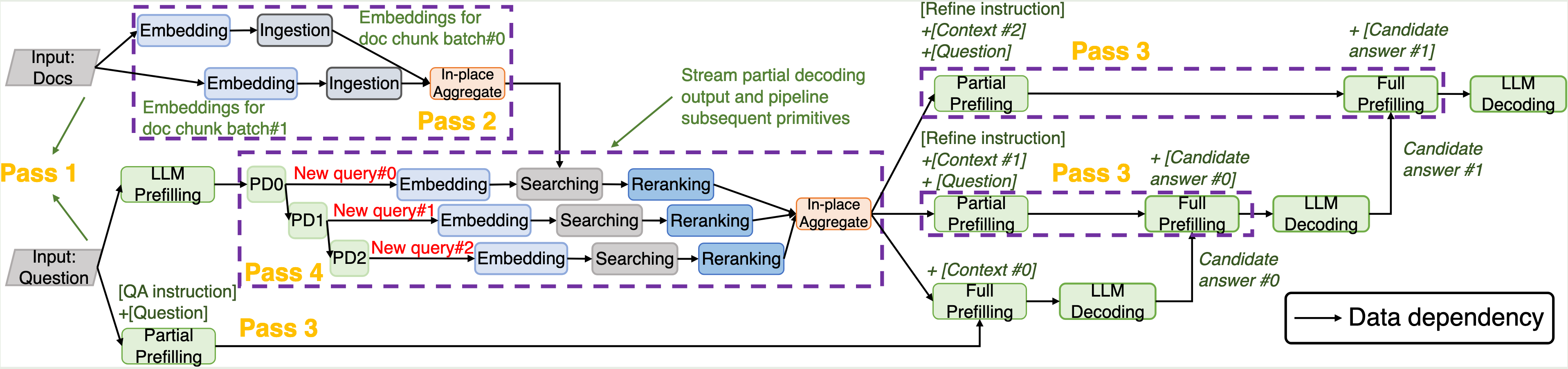
这篇工作关注LLM应用的端到端性能优化。首先提出了primitive-level dataflow graph对请求的工作流进行抽象。然后基于这个dataflow graph进行细粒度的调度和优化,例如并行化和流水线。与现有系统相比实现2.09X的加速。
背景和动机
我们与LLM交互发生了变化,从最初的chatbot到现在利用LLM完成复杂任务(例如:RAG,Agent等)。
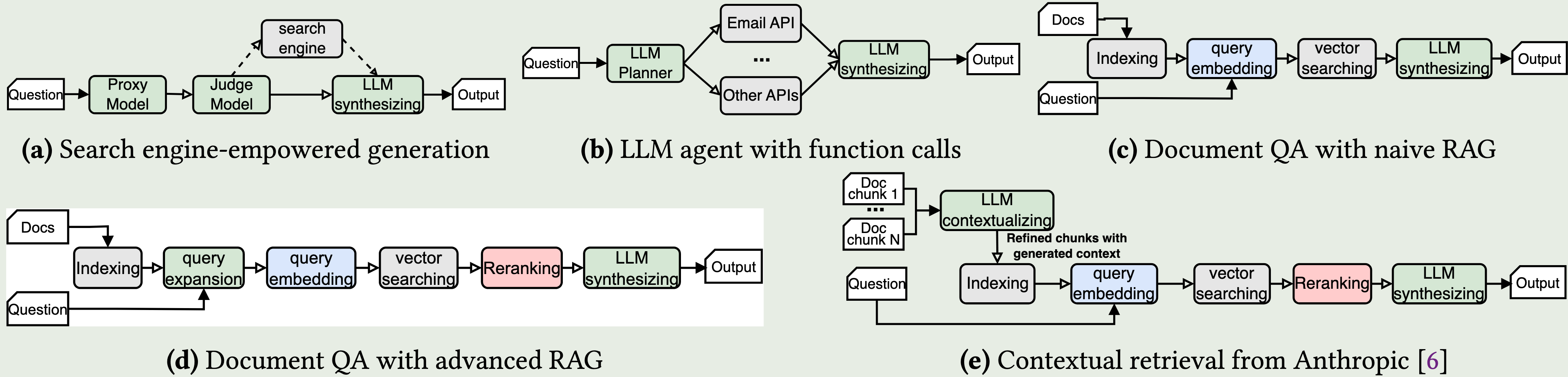
在LLM应用中,非LLM操作(例如:数据检索,网络搜索,调用API,索引构建等)占据了大部分执行时间。这对LLM的推理加速提出了新的需求。
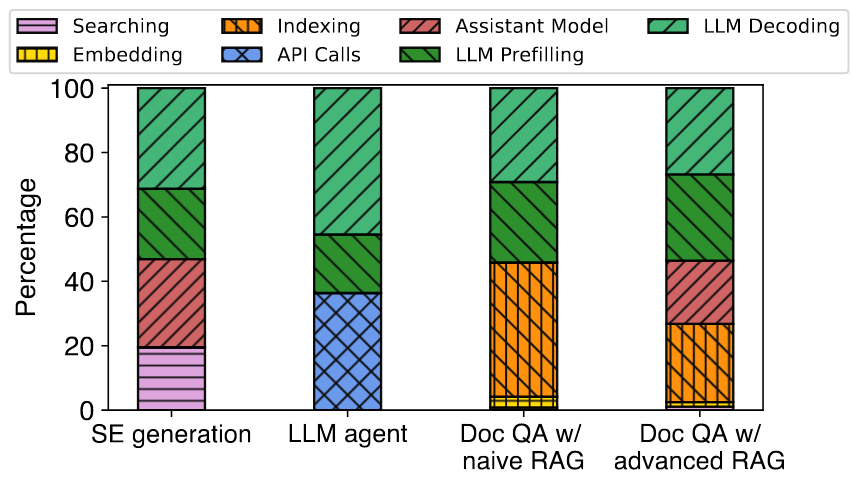
首先,现有LLM应用开发框架(Langchain,LLamaindex)以模块为粒度顺序调度,忽略了模块之间的依赖和计算特点,从而限制了对复杂工作流的优化。
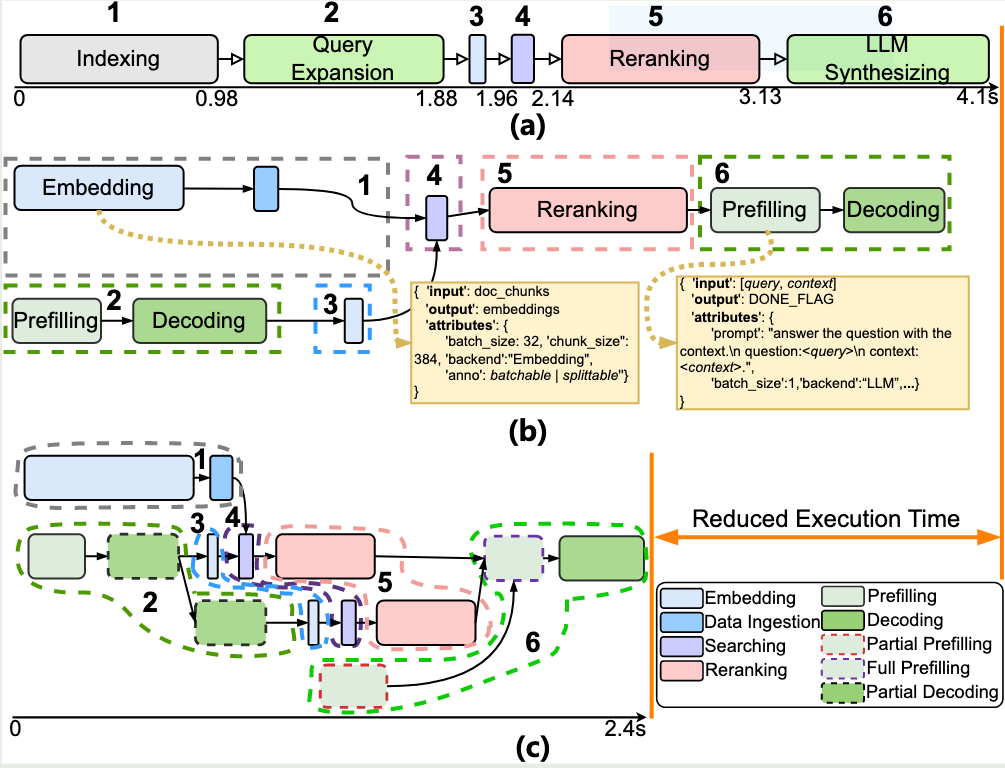
其次,面向request-level优化的推理后端与用户感知的application-leve的性能之间的不匹配。
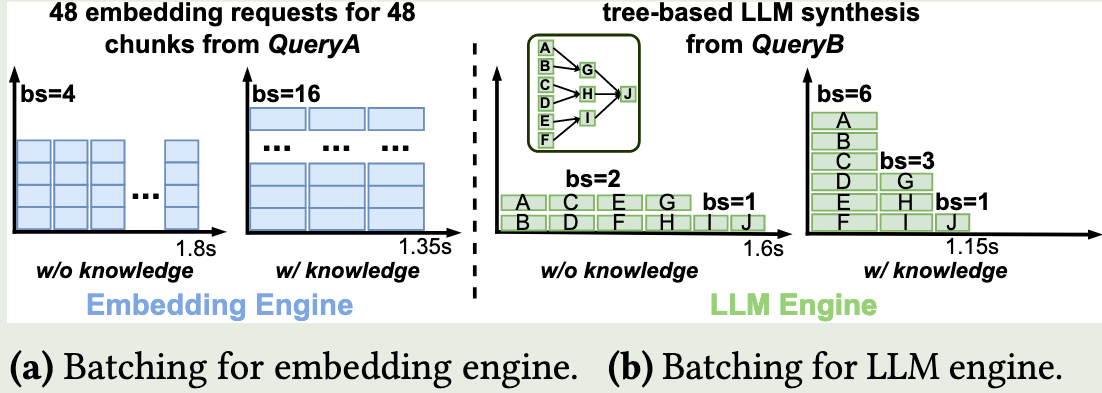
例如,在对文档进行embedding,当bs=4时每个embedding latency最低,但是bs=16整体embedding module的latency最低;在对tree-based的文档进行总结时,由于后端不感知前端执行的依赖,固定bs和顺序调度是次优的。
KV Cache Offloading
CacheAttention [ATC24]
Cost-efficient large language model serving for multi-turn conversations with CachedAttention [paper] [author]
FlashGen [ASPLOS25]
Accelerating LLM Serving for Multi-turn Dialogues with Efficient Resource Management [paper]
这片论文探讨了LLM推理服务在多轮对话场景下对计算和存储资源管理。
看完最大的收获是:本文讨论了队头阻塞导致的GPU内存资源利用率低的问题,虽然解决方法比较简单,但是确实没有在其他论文看到过;
本文的写作也值得学习,问题motivate的很清晰(分层缓存和请求调度问题),技术(Flash-Cache,Flash-Sched)也和两个问题一一对应。
动机
多轮对话也属于long-context 问题, 随着对话轮数的增加,prompt的长度显著上升,即prompt amplification problem。有限的GPU内存无法缓存所有对话的KV Cache,因此需要利用host memory,Disk来缓解KV Cache的存储压力。
此外,现有LLM推理服务采用FCFS来调度请求,当GPU剩余显存无法满足队首请求的需求,所有请求将被搁置,即使队列中有其他短请求可以执行。这就是队头阻塞导致的GPU资源利用低的问题。
解决方案
FlashGen-Cache:多层存储kv cache。
这里主要讨论了GPU和host memory,GPU和Disk之间的KV Cache保存和加载的问题。
核心的思路就是尽可能overlap计算和传输(overlap不了的话,就构造一些计算任务来overlap),以及采用proactive(inclusive)来主动备份KV Cache(GPU=>CPU, CPU=>Disk),利用host momory作为GPU和Disk的中转站(请求到达的时候,就主动的从Disk加载KV Cache到中转站)减少Disk数据加载延迟。
这些也是比较常用的方法,例如在RAGCache,CacheAttention也有类似的讨论。
FlashGen-Sched:通过请求重排序来高效利用GPU资源。
如下图所示,由于队头阻塞导致资源利用率低的问题,其中GPU的内存利用率平均为88%。
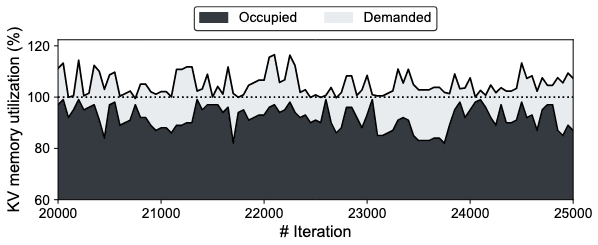
解决队头阻塞问题的方法比较直观:当发生队头阻塞的时候,贪心的执行下一个显存需求足够的请求。,当显存空间足够执行队头长请求(有其他请求完成),被提前调度的请求所占用的显存空间会被立即回收,用来执行队头长请求,防止Starvation问题。
经验
为什么在缓存历史KV Cache不能高效利用GPU内存?
高请求负载下意味着更高的内存争用。
在多轮对话场景下(或者用户和agent交互下),用户会花一些时间用来理解输出和输入下一个问题。这对利用GPU缓存的时间局部性带来了挑战。
在实验中作者模拟了用户交互的时间,即在两个对话中间插入间隔时间。根据[1],人类一分钟可以阅读300个单词,来估算每个token的时间 $1minute/300words=200ms$,间隔时间当前prompt长度+上一个输出token数量之和,然后乘以200ms。
[1] Keith Rayner. 1978. Eye Movements in Reading and Information Processing.
Strata [Arxiv25]
Strata: Hierarchical Context Caching for Long Context Language Model Serving [paper] [author]
这篇工作应该是作者在SGLang中实现分层KV Cache形成的一篇工作,[sglang issue #2693]。
本文讨论了一个比较有意思的问题:LLM推理服务的“Delay Hit”问题,即多个请求具有相同的前缀,如果把这些请求打包在一起调度,会导致冗余计算。这个点在我之前的代码中也遇到过,和作者解决思路差不多,就是优先处理其中一个请求,推迟后续请求的调度。
背景
用户的请求通常具有相同的前缀(例如system promt,hot retrieve in RAG等)。利用这一特点,通过缓存请求的KV Cache我们可以有效减少冗余KV Cache计算。一方面随着模型上下文窗口的增加,每个请求的KV Cache越来越大,另一方面GPU有限的内存无法存储所有用户的请求。因此将KV Cache从GPU offload 到host momory和Disk是long-context LLM推理的普遍的做法。
动机
本文探讨了在offloading KV Cahce场景下的两个问题:
KV Cache传输的带宽利用低。
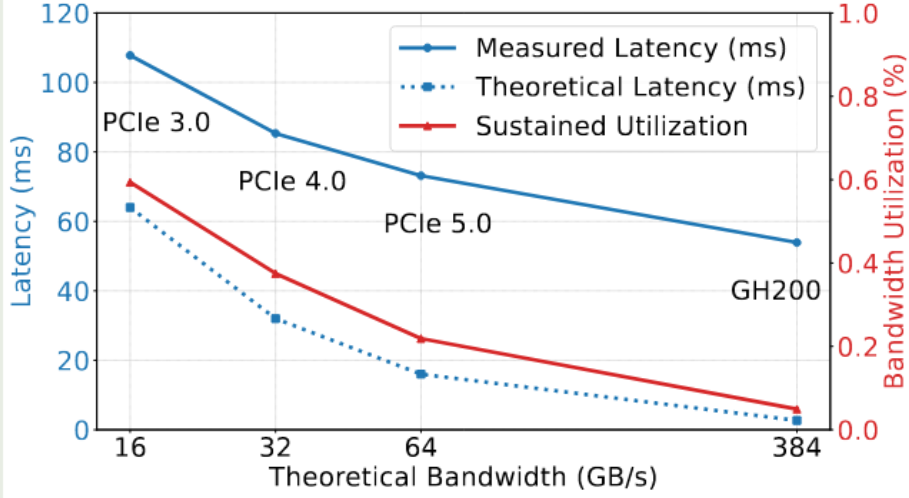
为了解决LLM推理过程中内存碎片的问题, vLLM提出了分页管理KV Cache的技术,这也成了现有LLM推理框架的默认设置。为了保证内存的利用率和缓存命中率,页面大小通常比较小,例如TensorRT-LLM的
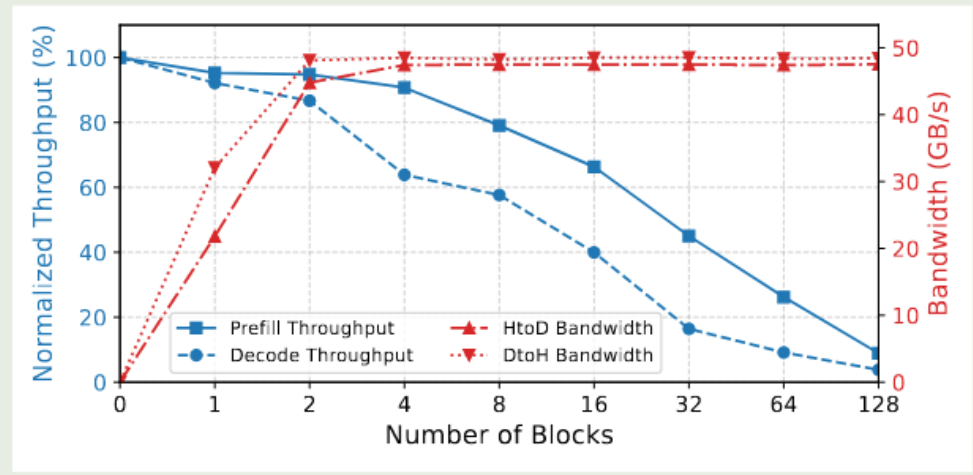
page size =32, vllm的page size = 16,SGLang的page size = 1。然而这种小的page size对传输并不友好。作者测试了不同通信带宽下,从CPU到GPU加载KV Cache的延迟和带宽利用率。可以看到,在PCIe 5.0上带宽利用率仅为22%。在更高的互连带宽下,例如Grace-Hopper下,带宽利用率低于5%。
作者在分析传输带宽问题的思路可以借鉴下:首先根据李特尔法则(Little‘s Law),系统在稳定状态下的平均并发数量为 $C=\lambda \cdot L$,其中$\lambda$表示请求到达速率,$L$表示每个请求的平均延迟。此时吞吐量$X=\lambda \cdot S$,其中$S$表示每个请求的平均数据大小。合并上面两个公式, $X=C\cdot S/L$,因此增大并行I/O请求数量,使用更大的块大小和降低每次操作的延迟(使用更快的存储介质)可以提高系统的吞吐量。
KV Cache延迟命中问题
在计算机网络缓存中,延迟命中(delay hit phenomenon)是指:当一个请求发生cache miss时,请求从后端服务加载对象。如果在这个缓存miss还没完成时,又有多个请求访问同一个对象,这些请求不能立即命中,只能排队等待第一个miss被填充。
在LLM推理中也存在相同的问题,例如,在高并发的请求中,多个请求具有相同的前缀,当这些请求被打包为一个batch时,就会存在冗余计算。一些推理框架(SGLang,NanoFlow)采用异步调度batch的方法,即推对一个batch请求计算的同时,异步的构建下一个batch,来减少调度对推理性能的影响。在这种情况下, 如果下个batch和上个batch存在前缀共享,那么延迟命中的问题就会被进一步放大。
解决方案
GPU-assisted I/O实现高效的读写
GPU辅助I/O具有以下好处:1)GPU具有大量线程,可以同时发出大量读写操作来打满带宽;2)GPU-assisted I/O的读写粒度通常为128字节,比较适合单个page(千字节)的传输。3)利用轻量级I/O内核来实现灵活的内存layout转换。
然而,使用GPU-assisted I/O会和计算任务(prefill,decode)抢计算资源。作者对比了使用不同数量的block来做I/O kernel下系统的吞吐变化。发现当block = 1或2时,对计算的影响是可以接受的(5%)。因此对于从CPU加载KV Cache使用block = 2(critical path),GPU写CPU使用block = 1(non-critical path)。
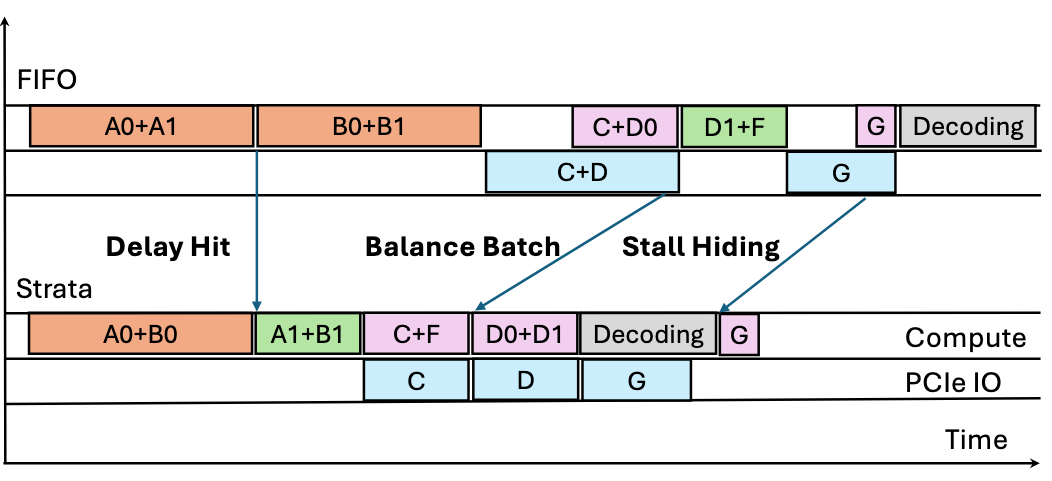
Cache Aware Scheduling
Deferral on Delay Hit:通过为请求进行标记来缓解“延迟命中”的问题。节点状态分为
in-queue和in-flight。被调度的请求涉及的token首先被标记为in-queue,后续命中in-queue的请求将被推迟。当请求执行的时候,节点状态从in-queue切换到in-flight。作者设置阈值,只有超过一定数量的节点被命中(100个),才会被推迟调度。如图所示,A1和A0具有相同的前缀,A0被调度的时候,前缀节点被标记为
in-queue,因此A1会被延迟调度。Balance Batch Formation:当调度的请求都需要从CPU加载KV Cache会引发loading stall(例如,同时调度C和D0)。此外将具有相同前缀的请求打包在一个batch中可以减少内存占用和冗余计算,本文将这种请求称为”bundle hit”。
balance batch通过设置阈值(load/compute = 100)来对请求进行调度,当加入请求满足loading bound限制,将被添加到batch中,随后对所有候选请求执行bundle hit检测,将具有相同前缀的请求加入到batch中。如果请求超过loading bound将被放到一个低优先级的队列,当调度完成之后,batch没有被填满再将这些loading比较重的请求放入队列中。
Hide Loading Stall with Bubble Filing:但不可避免发生loading stall时,本文通过将loading和decoding overlap来尽可能隐藏loading的开销。
Sparse Attention/Long context
LM-infinite
Longformer [Arxiv20]
StreamingLLM [ICLR24]
Efficient Streaming Language Models with Attention Sinks [code] [paper]
解决的问题
LLM在长上下文的效率和效益的问题:
- 长上下文的计算和内存开销大。
- LLM在上下文长度超过预训练长度时,生成质量差。
核心idea
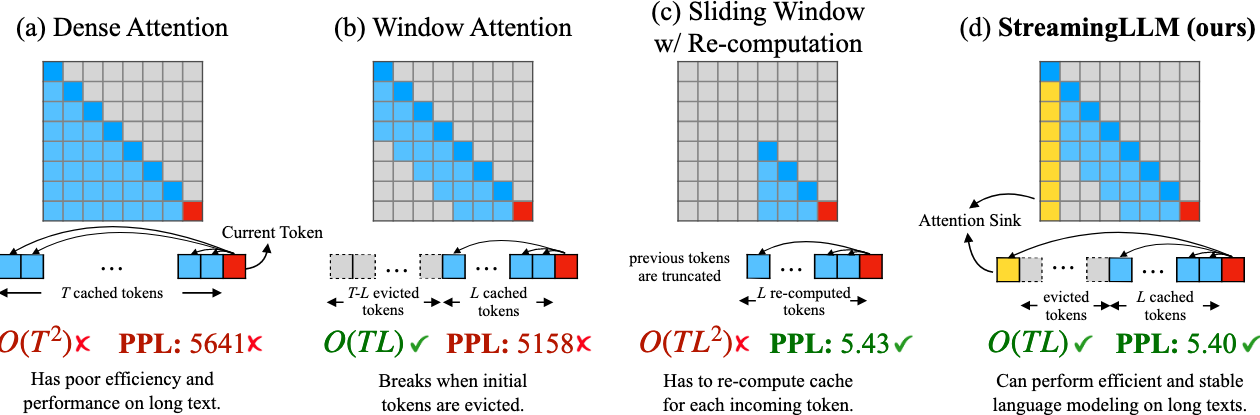
- Dense Attention:计算复杂度高,当上下文长度超过预训练长度,模型表现差。
- Window Attention:计算复杂度低,当上下文长度超过缓存长度(initial token)被驱逐时,模型表现差。
- Sliding Window w/ Re-computation:计算复杂度中等,通过重新计算,保留了initial token的影响,模型表现良好。
- StreamingLLM:在Window Attention的基础上,引入了对initial token的注意力计算,兼顾推理速度和模型生成质量。
Streamllm的方法主要来自于一个观察:
”Attention sink“:作者发现LLM对初始token的注意力关注较高。
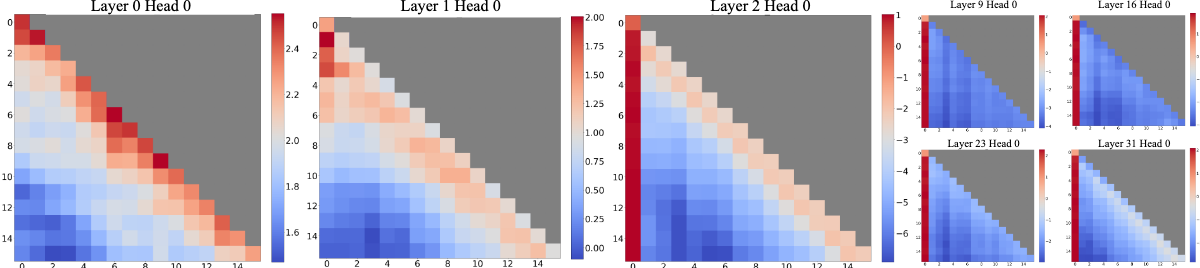
作者对Attention sink给了一个解释:
LLM的注意力计算,保证所有token的注意力之和为1,即使当前token只需要根据自己就可以推测出下一个token,由于softmax的设计,还是需要将一些注意力分散到其他token上去。
由于LLM的自回归特性,开始的token可以被后面所有tokne注意力到,因此LLM对initial token的关注更高,进而在训练的过程中,赋予inital token特殊的含义。
细节
按照在cache中的位置,重新分配token的位置信息,以保成相对位置的正确性。
如下图所示,当生成 token 9的时候,每个token的位置为[0, 1, 2, 3, 4, 5, 6, 7]而不是[0, 1, 2, 3, 6, 7, 8, 9]。
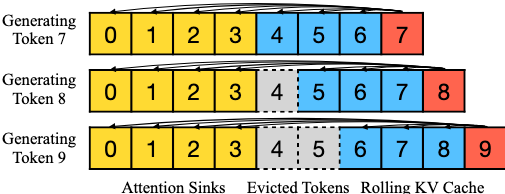
key tensor的缓存和使用
对于RoPE,在应用 rotray 变化前缓存 key tensor,在加载的时候对其rotray。
对于ALiBi,在注意力分数上添加一个linear bias。
Training
MEMO [SIGMOD25]
MEMO: Fine-grained Tensor Management For Ultra-long Context LLM Training [paper]
Malleus [SIGMOD25]
Malleus: Straggler-Resilient Hybrid Parallel Training of Large-scale Models via Malleable Data and Model Parallelization [paper]

