
 PhD student @ Northeastern University
PhD student @ Northeastern UniversityI am a third-year Ph.D. student in Computer Science at Northeastern University (China), working in the iDC-NEU Group under the supervision of Prof. Yanfeng Zhang. Prior to that, I received my M.S. in Computer Science from Northeastern University (China) and my B.S. from Henan University.
My research interests broadly lie in building efficient systems to support the training of graph neural networks (GNNs), with a current focus on system-level optimizations for AI workloads.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Northeastern UniversityPh.D. StudentSep. 2023 - present
-
Northeastern UniversityM.S. in Computer ScienceSep. 2021 - Jul. 2023
-
 Henan UniversityB.S. in Computer ScienceSep. 2017 - Jul. 2021
Henan UniversityB.S. in Computer ScienceSep. 2017 - Jul. 2021
Honors & Awards
-
National Scholarship of China2024
-
The champion in China’s first CCF Graph Computing Challenge2023
Selected Publications (view all )
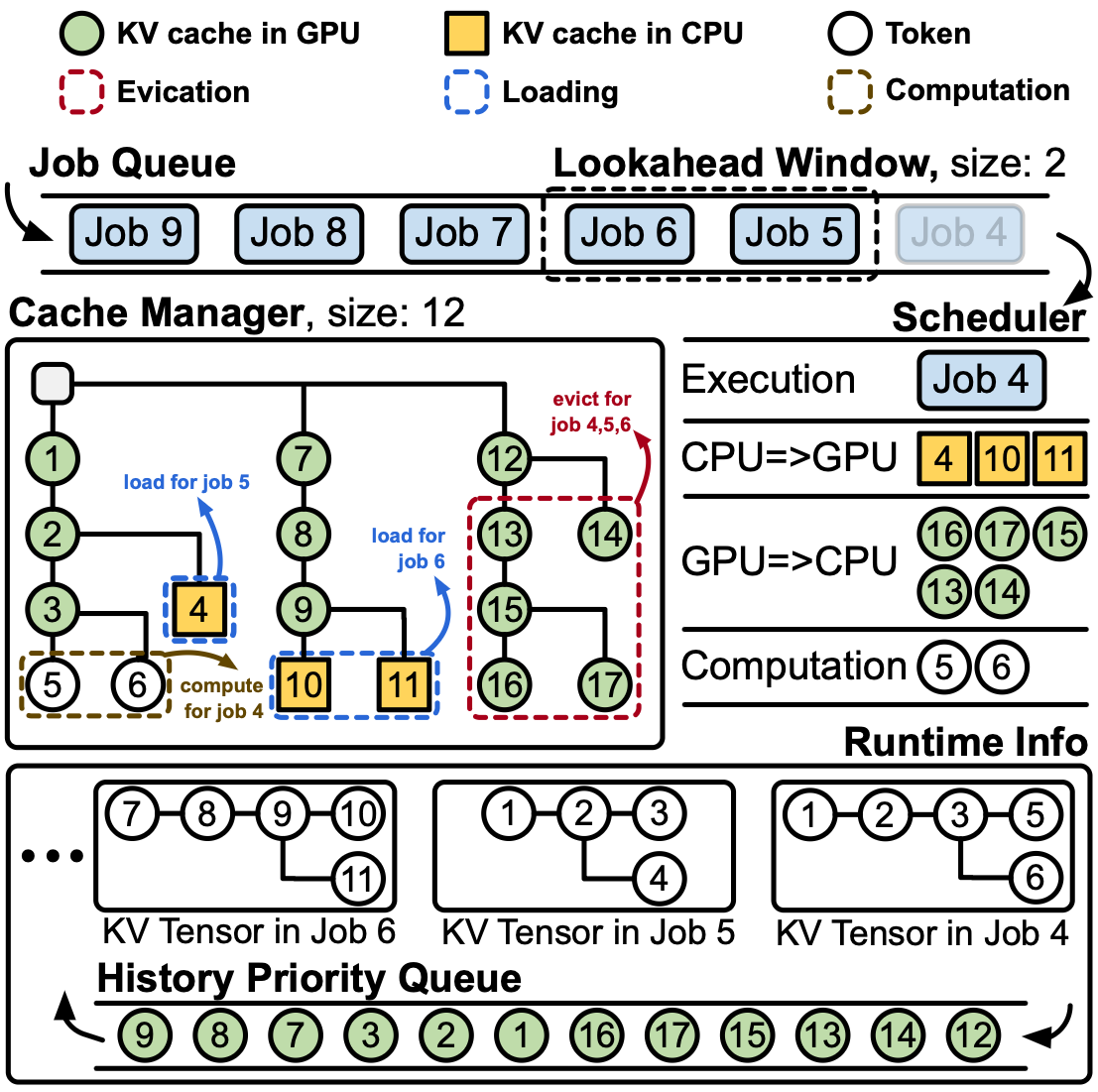
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
![NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]](/assets/images/covers/sigmod-neutronrag.png)
NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]
Peizheng Li, Chaoyi Chen, Hao Yuan, Zhenbo Fu, Xinbo Yang, Qiange Wang, Xin Ai, Yanfeng Zhang, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2025
Existing RAG tools typically use a single retrieval method, lacking analytical capabilities and multi-strategy support. To address these challenges, we introduce NeutronRAG, a demonstration of understanding the effectiveness of RAG from a data retrieval perspective. NeutronRAG supports hybrid retrieval strategies and helps researchers iteratively refine RAG configuration to improve retrieval and generation quality through systematic analysis, visual feedback, and parameter adjustment advice.
NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]
Peizheng Li, Chaoyi Chen, Hao Yuan, Zhenbo Fu, Xinbo Yang, Qiange Wang, Xin Ai, Yanfeng Zhang, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2025
Existing RAG tools typically use a single retrieval method, lacking analytical capabilities and multi-strategy support. To address these challenges, we introduce NeutronRAG, a demonstration of understanding the effectiveness of RAG from a data retrieval perspective. NeutronRAG supports hybrid retrieval strategies and helps researchers iteratively refine RAG configuration to improve retrieval and generation quality through systematic analysis, visual feedback, and parameter adjustment advice.
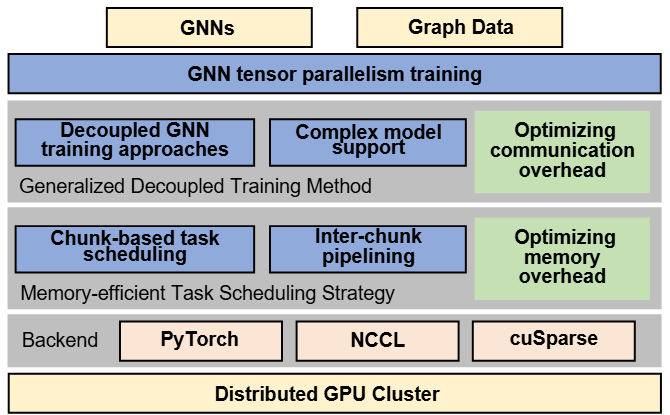
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
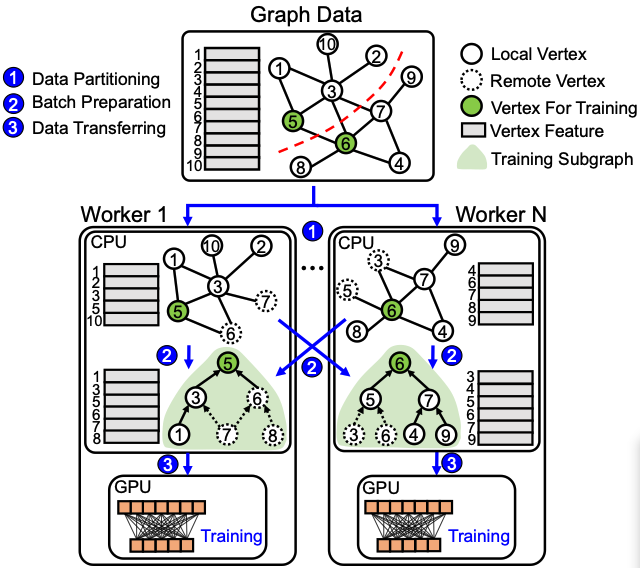
Comprehensive Evaluation of GNN Training Systems: A Data Management Perspective
Hao Yuan, Yajiong Liu, Yanfeng Zhang, Xin Ai, Qiange Wang, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
This paper reviews GNN training from a data management perspective and provides a comprehensive analysis and evaluation of the representative approaches. We conduct extensive experiments on various benchmark datasets and show many interesting and valuable results. We also provide some practical tips learned from these experiments, which are helpful for designing GNN training systems in the future.
Comprehensive Evaluation of GNN Training Systems: A Data Management Perspective
Hao Yuan, Yajiong Liu, Yanfeng Zhang, Xin Ai, Qiange Wang, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
This paper reviews GNN training from a data management perspective and provides a comprehensive analysis and evaluation of the representative approaches. We conduct extensive experiments on various benchmark datasets and show many interesting and valuable results. We also provide some practical tips learned from these experiments, which are helpful for designing GNN training systems in the future.