基础知识
行列式
二阶行列式
$\begin{vmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ \end{vmatrix} = a_{11}a_{22} - a_{12}a_{21}$
三阶行列式
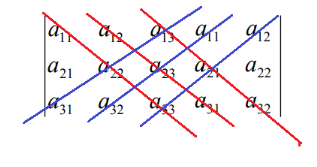
对于更高阶的行列式,一般将行列式转为三角形,这样只用计算对角线的乘积即可。
余子式
$n$阶行列式,把第$a_{ij}$所在的行列删除,留下的$n-1$阶行列式称为余子式,记为$M_{ij}$。
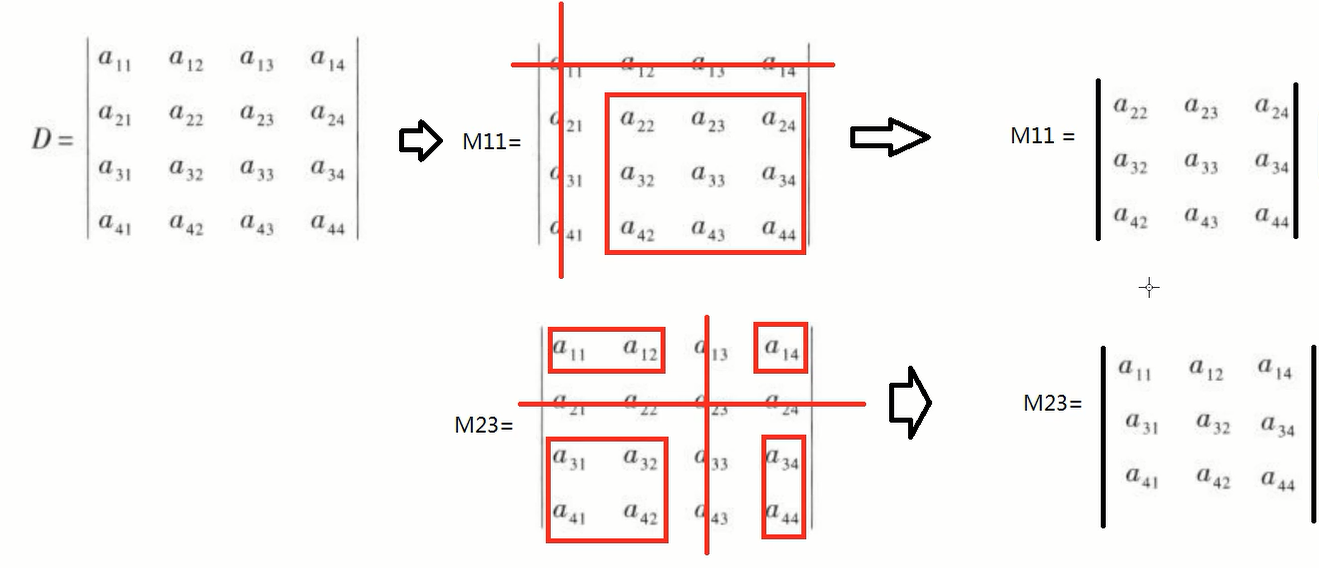
代数余子式
代数余子式的$A_{ij} = -1^{i+j}M_{ij}$。
伴随矩阵
代数余子式的转置称为伴随矩阵,只有方阵才有伴随矩阵,记为$A^*$。
伴随矩阵的性质:
$AA^* = A^*A = |A|E$
$A^{-1} = \frac{1}{|A|}A^*(存在A^{-1})$
$(A^*)^{-1}=(A^{-1})^*=\frac{1}{|A|}A$
$|A^*|=|A|^{n-1}$
$(kA)^*=k^{n-1}A^*$
矩阵的逆
$A^{-1} = \frac{1}{|A|}A^*(存在A^{-1})$
$A^{-1} = \frac{1}{|A|}A^{*}=\frac{1}{ad-bc}\begin{bmatrix}d &-b\ -c & a\end{bmatrix}$
例:
线性代数的本质
什么是向量
向量对于不同的学科有不一样的定义。
物理中的向量有长度和方向决定,长度和方向不变可以随意移动,它们表示的是同一个向量。
计算机中的向量更多的是对数据的抽象,可以根据面积和价格定义一个房子$\begin{bmatrix}100m^2\\700000¥\end{bmatrix}$。
数学中的向量可以是任意东西,只要保证两个向量的相加$\vec v + \vec w$以及数字和向量相乘$2\vec v$是有意义的即可。
线性代数中的向量可以理解为一个空间中的箭头,这个箭头起点落在原点。如果空间中有许多的向量,可以点表示一个向量,即向量头的坐标。
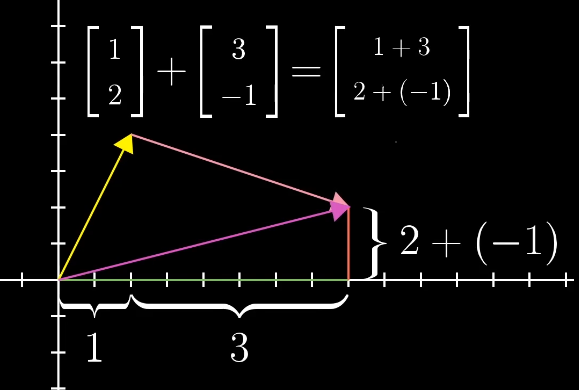
向量的基本运算
向量的加法:可以理解为在坐标中两个向量的移动。
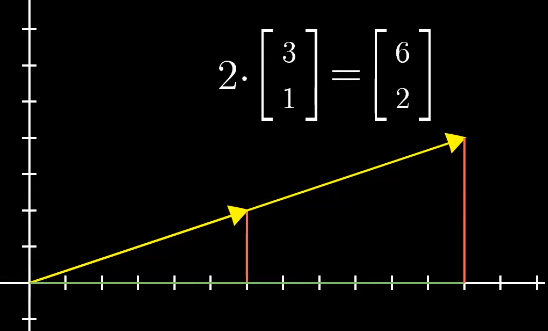
数字和向量相乘:可以理解为向量的缩放。
线性组合、张成空间、基
线性组合
两个数乘向量称为两个向量的线性组合$a\vec v+ b\vec w$。
两个不共线的向量通过不同的线性组合可以得到二维平面中的所有向量。
两个共线的向量通过线程组合只能得到一个直线的所有向量。
如果两个向量都是零向量那么它只能在原点。
张成空间
所有可以表示给定向量线性组合的向量的集合称为给定向量的张成空间(span)。
一般来说两个向量张成空间可以是直线、平面。
三个向量张成空间可以是平面、空间。
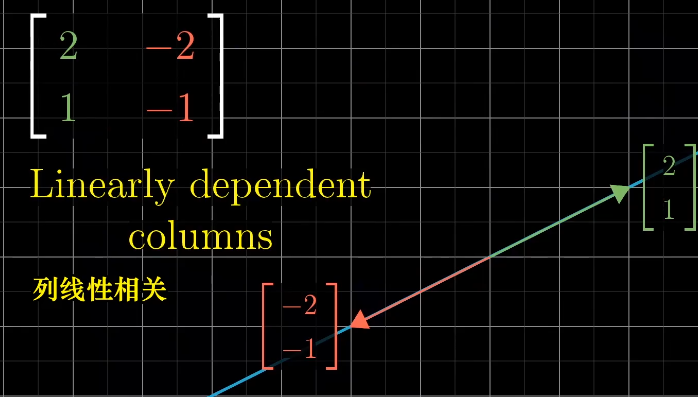
如果多个向量,并且可以移除其中一个而不减小张成空间,那么它们是线性相关的,也可以说一个向量可以表示为其他向量的线性组合$\vec u = a \vec v + b\vec w$。
如果所有的向量都给张成的空间增加了新的维度,它们就成为线性无关的$\vec u \neq a \vec v + b\vec w$。
基
向量空间的一组及是张成该空间的一个线性无关向量集。
矩阵与线性变换
严格意义上来说,线性变换是将向量作为输入和输出的一类函数。
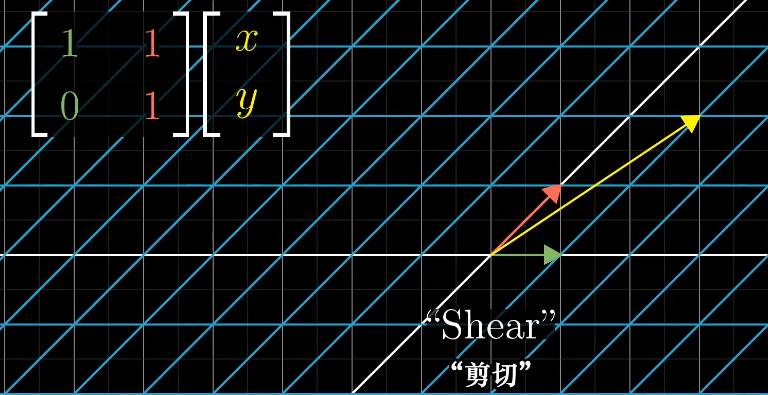
变化可以多种多样,线性变化将变化限制在一个特殊类型的变换上,可以简单的理解为网格线保持平行且等距分布。
线性变化满足一下两个性质:
- 线性变化前后直线依旧是直线不能弯曲。
- 原点必须保持固定。

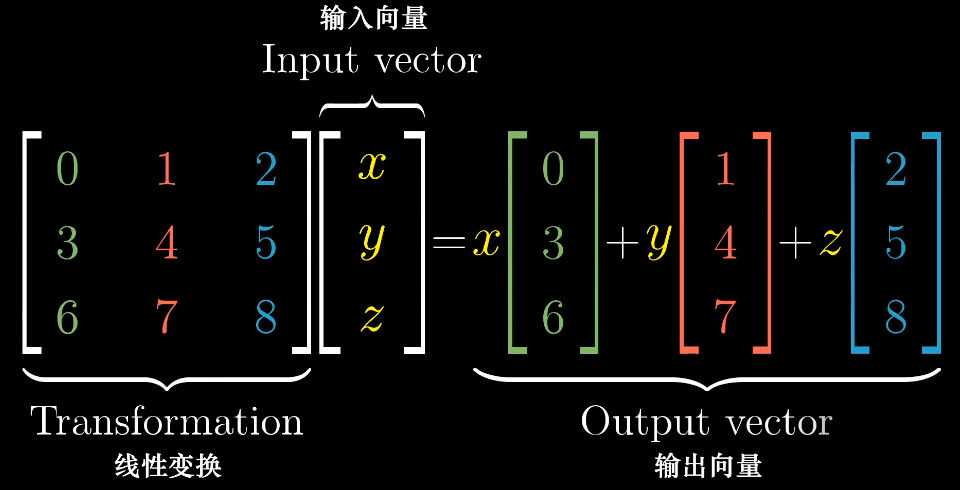
可以使用基向量来描述线性变化:
通过记录两个基向量$\hat{i}$,$\hat{j}$的变换,就可以得到其他变化后的向量。
已知向量$\vec v = \begin{bmatrix}-1\\2\end{bmatrix}$
变换之前的$\hat i$和$\hat j$:

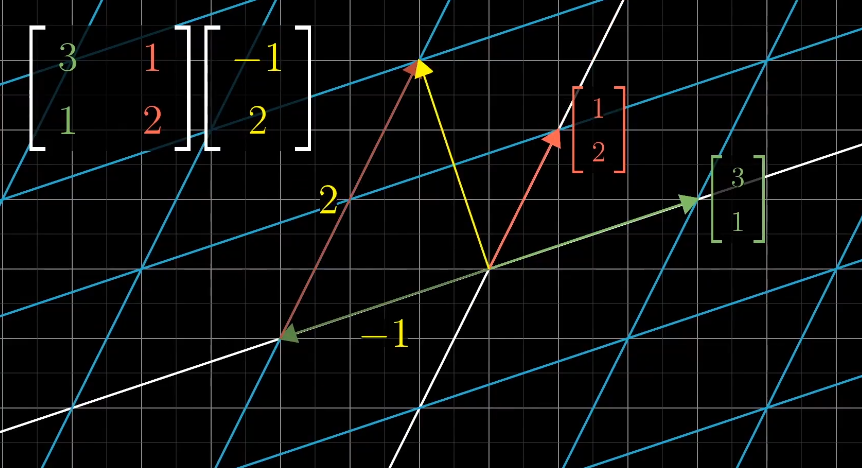
如果变化后的$\hat{i}$和$\hat{j}$是线性相关的,变化后向量的张量就是一维空间:
矩阵乘法与线性变换复合的联系
线性变化的复合
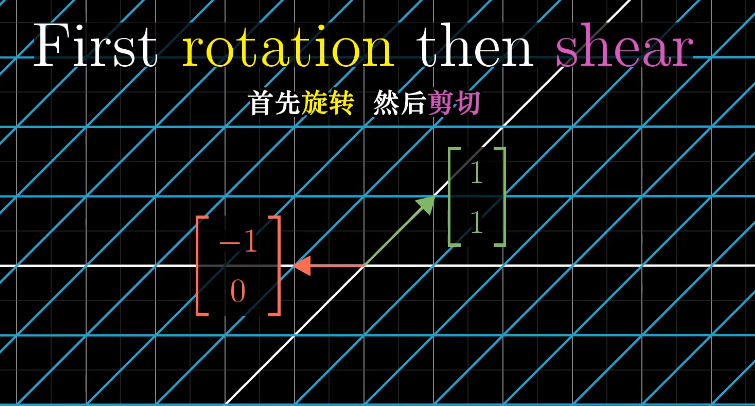
如何描述先旋转再剪切的操作呢?
一个通俗的方法是首先左乘旋转矩阵然后左乘剪切矩阵。

两个矩阵的乘积需要从右向左读,类似函数的复合。
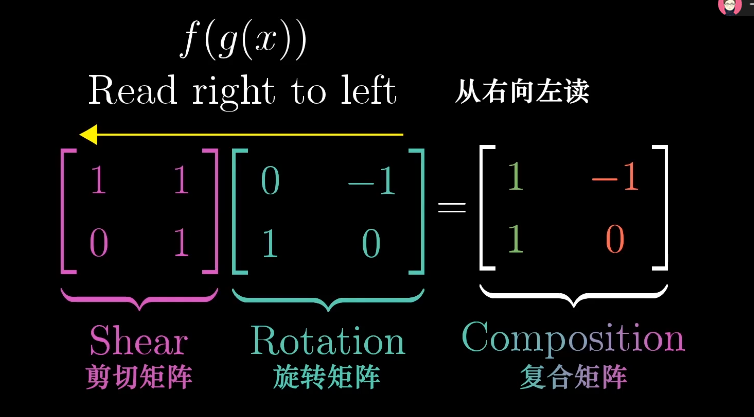
这样两个矩阵的乘积就对应了一个复合的线性变换,最终得到对应变换后的$\hat{i}$和$\hat{j}$。
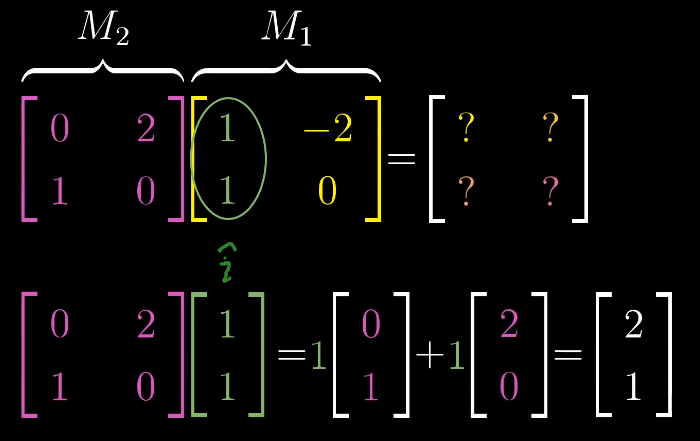
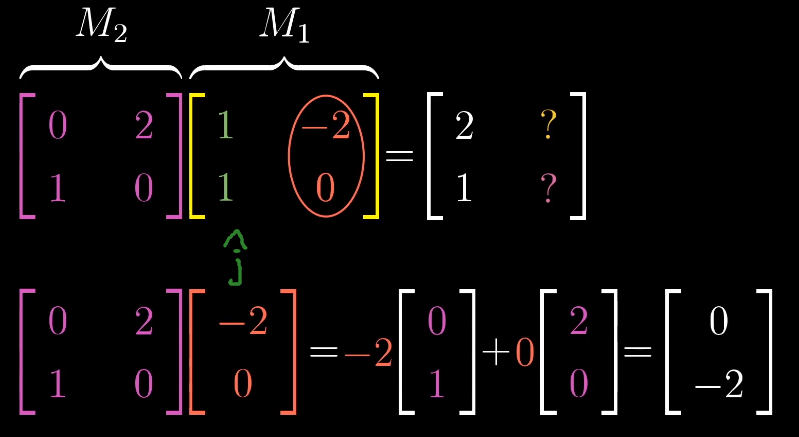
这一过程具有普适性:
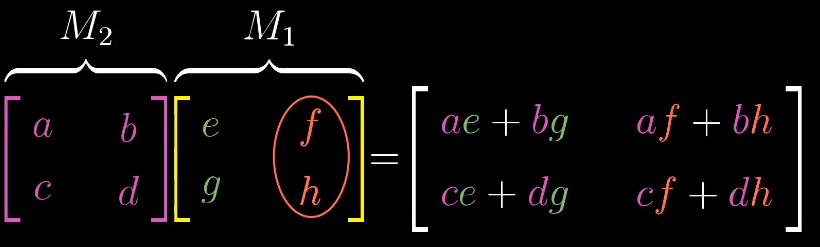
矩阵乘法的顺序
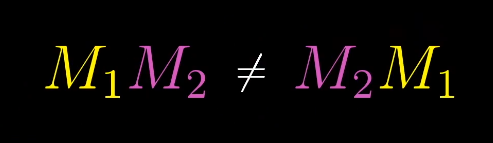

如何证明矩阵乘法的结合性?
$(AB)C = A(BC)$
根据线性变化我们可以得出,矩阵的乘法都是以CBA的顺序变换得到,所以他们本质上相同,通过变化的形式解释比代数计算更加容易理解。
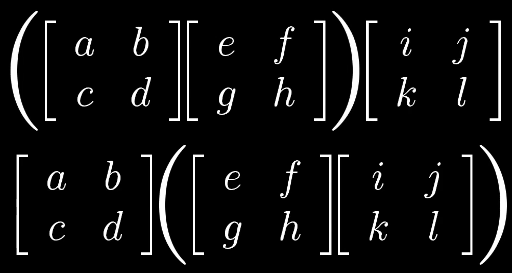
三维空间的线性变化
三维的空间变化和二维的类似。
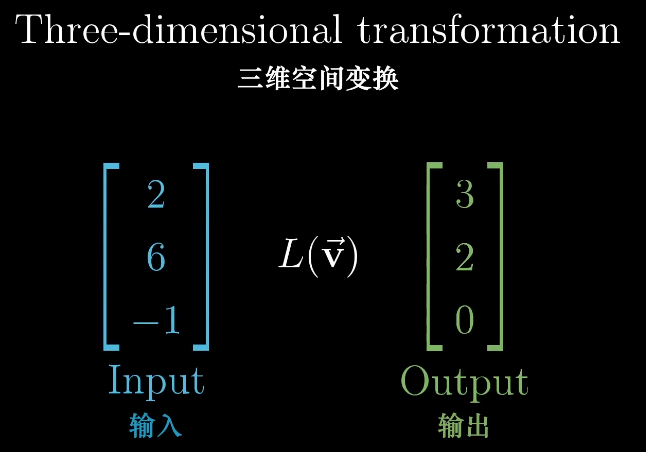
同样跟踪基向量的变换,能很好的解释变换后的向量,同样两个矩阵相乘也是。
行列式
行列式的本质
行列式的本质是计算线性变化对空间的缩放比例,具体一点就是,测量一个给定区域面积增大或减小的比例。
单位面积的变换代表任意区域的面积变换比例。
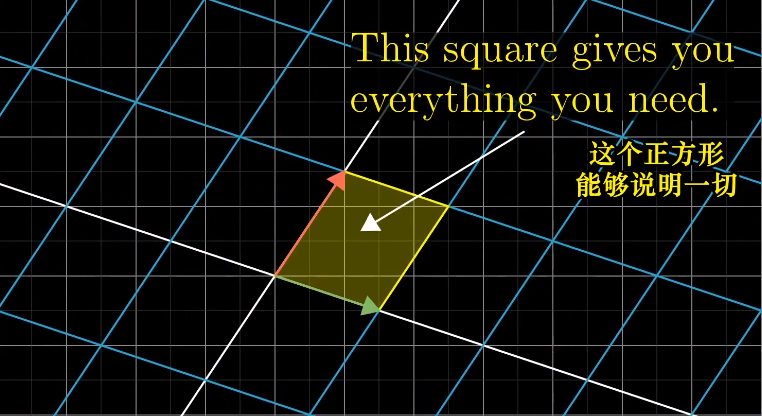
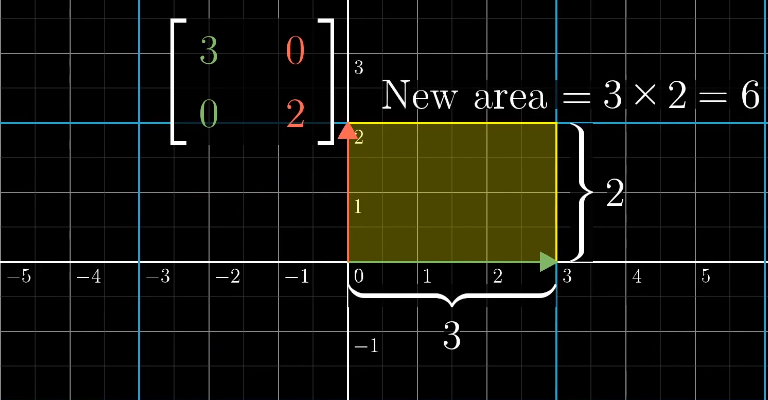
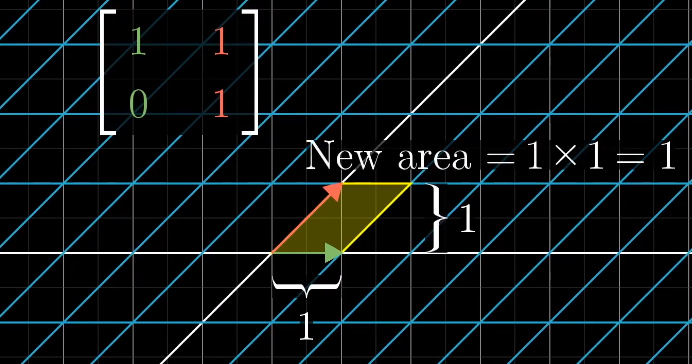
行列式的值表示缩放比例。


行列式为什么有负值呢?

三维空间的行列式类似,它的单位是一个单位1的立方体。
三位空间的线性变换,可以使用右手定则判断三维空间的定向。如果变换前后都可以通过右手定则得到,那么他的行列式就是正值,否则为负值。
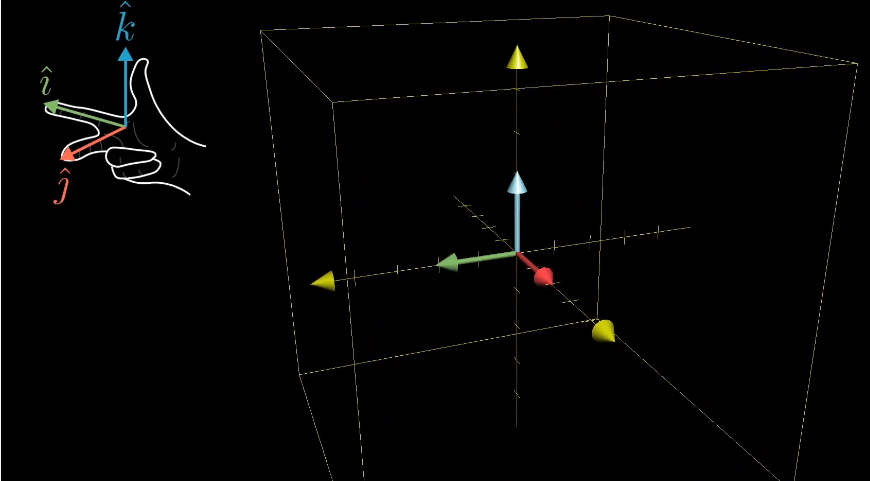
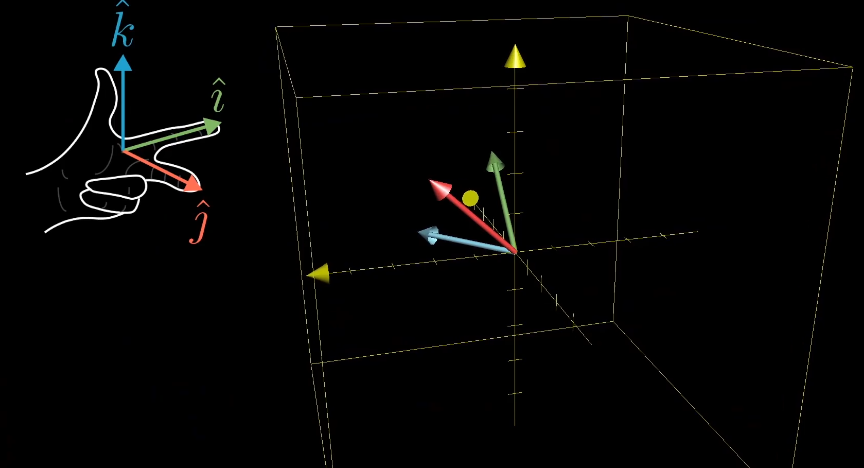
行列式的计算
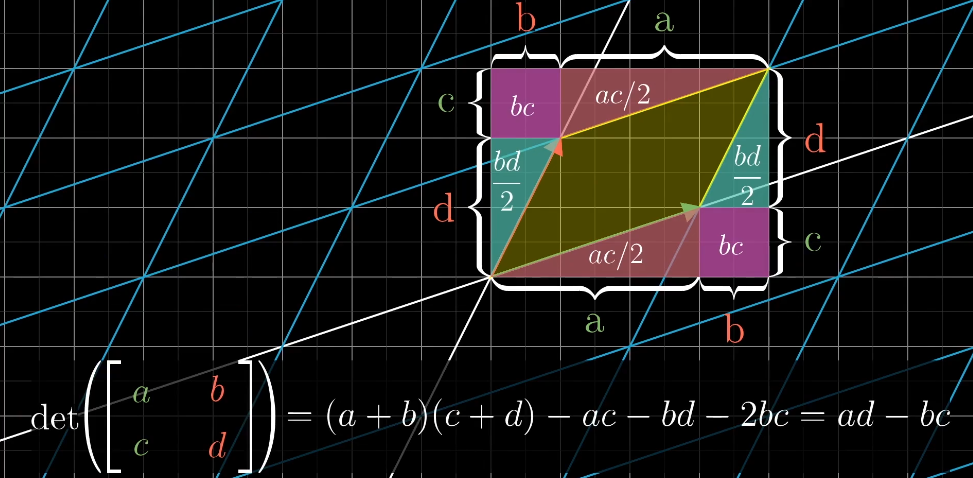
二阶行列式
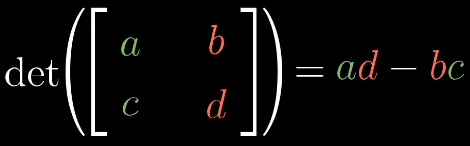
三阶行列式
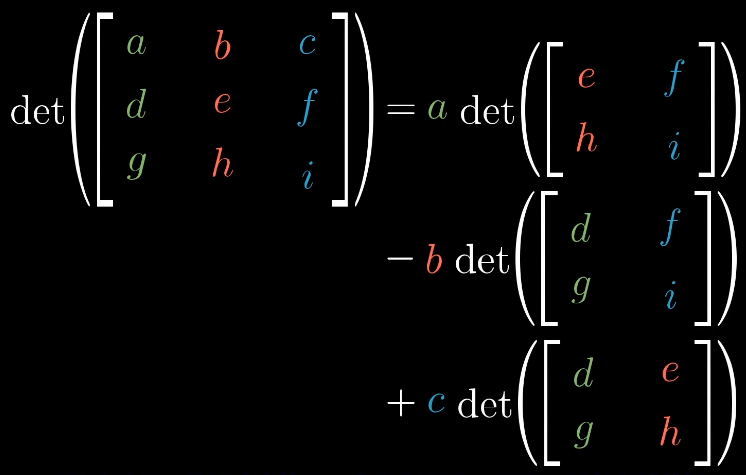
二阶行列式中a、d,表示横向和纵向的拉伸,b、c表示对角线的拉伸和压缩的情况。
逆矩阵、列空间、秩、零空间
线性方程组
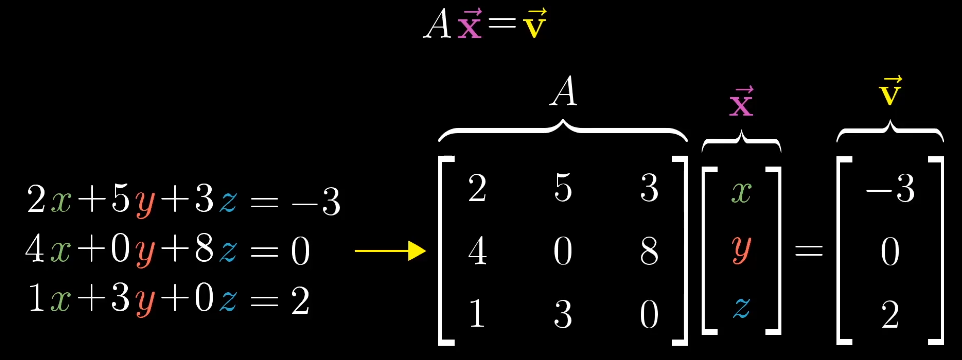
从几何的角度来思考,矩阵A表示一个线性变换,我们需要找到一个$\vec x$使得它在变换后和$\vec v$重合。
逆矩阵
矩阵的逆运算,记为$\vec A = \begin{bmatrix}3&1 \\0&2\end{bmatrix}^{-1}$,对于线程方程$A \vec x = \vec v $来说,找到$A^{-1}$就得到解$\vec x = A^{-1} \vec v$。
线性方程组的解
对于方程组$A\vec x = \vec v$,线性变换A存在两种情况:
$det(A) \neq0$:这时空间的维数并没有改变,有且只有一个向量经过线性变换后和$\vec v$重合。
$det(A) =0$:空间被压缩到更低的维度,这时不存在逆变换,因为不能将一个直线解压缩为一个平面,这样就会映射多个向量。但是即使不存在逆变换,解可能仍然存在,因为目标$\vec v$刚好落在压缩后的空间上。
秩
秩代表变换后空间的维度。
如果线性变化后将空间压缩成一条直线,那么称这个变化的秩为1;
如果线性变化后向量落在二维平面,那么称这个变化的秩为2。
列空间
所有可能的输出向量$A\vec v$构成的集合,称为列空间,即所有列向量张成的空间。
零空间(Null space)
所有的线性变化中,零向量一定包含在列空间中,因为线性变换原点保持不动。对于非满秩的情况来说,会有一系列的向量在变换后仍为零向量。
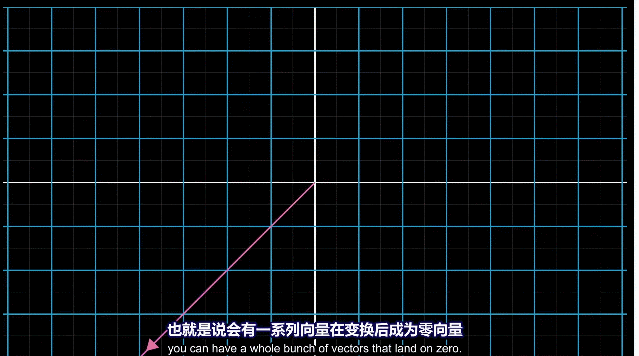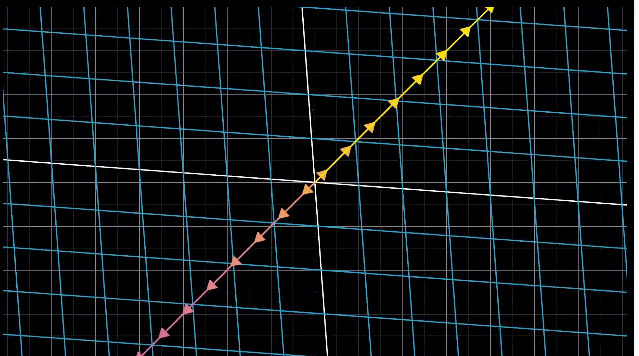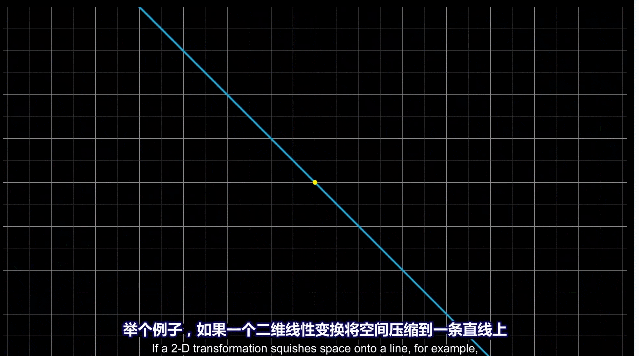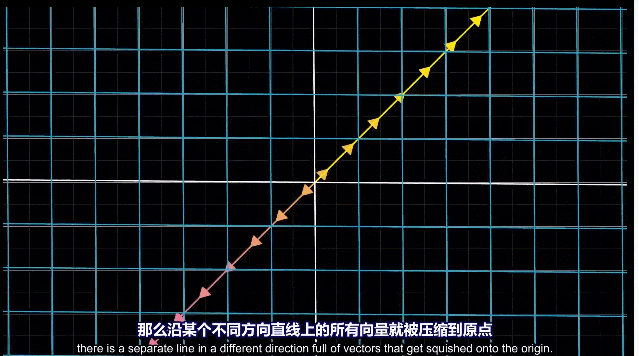
二维空间压缩为一条直线,一条线上的向量都会落到原点。
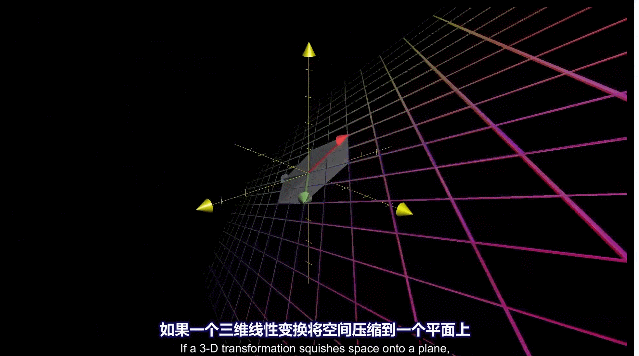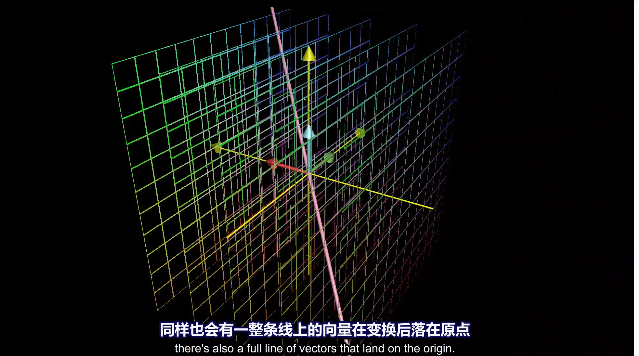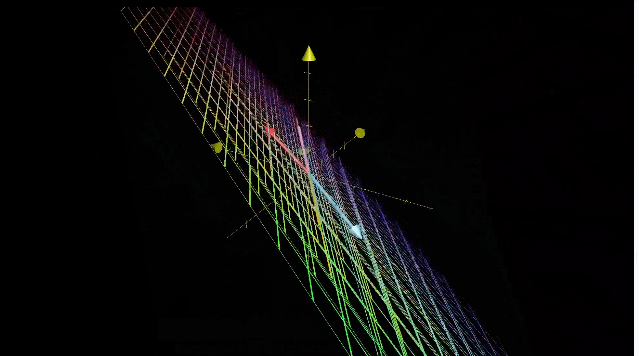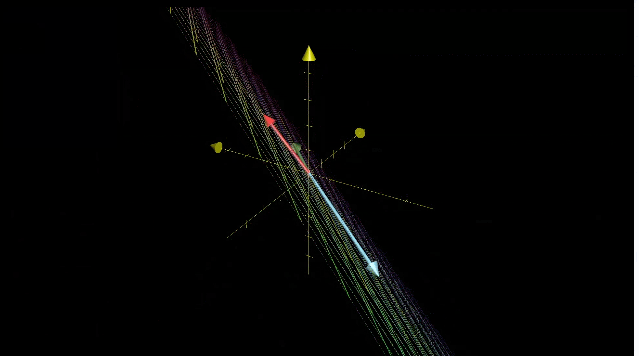
三维空间压缩为二维平面,一条线上的向量都会落到原点。
三维空间压缩为一条直线,整个平面上的向量都会落到原点。

当$A\vec x = \vec v$中的$\vec v$是一个零向量,即$A\vec x = \begin{bmatrix}0 \\0\end{bmatrix}$时,零空间就是它所有可能的解。
非方阵、不同维度空间之间的线性变换
不同维度的变换也是存在的。
一个$3\times2$的矩阵:$\begin{bmatrix}2&0\-1&1\-2&1 \end{bmatrix}$它的集合意义是将一个二维空间映射到三维空间上,矩阵有两列表明输入空间有两个基向量,有三行表示每个向量在变换后用三个独立的坐标描述。

一个$2\times 3$的矩阵:$\begin{bmatrix}3&1&4\1&5&9 \end{bmatrix}$则表示将一个三维空间映射到二维空间上。
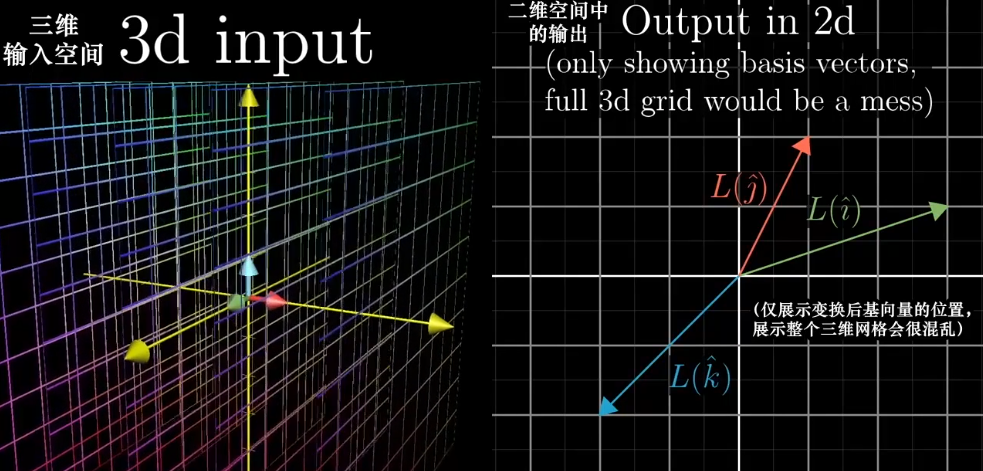
一个$1\times 2$的矩阵:$\begin{bmatrix}1&2 \end{bmatrix}$表示一个二维空间映射到一维空间。

点积与对偶性
点积
对于两个维度相同的向量,他们的点积计算为:$\begin{bmatrix}1\\2\end{bmatrix}\cdot\begin{bmatrix} 3\\4\end{bmatrix}=1\cdot3+2\cdot4=11$。
点积的几何解释是将一个向量向一个向量投影,然后两个长度相乘,如果为负数则表示反向。

为什么点积和坐标相乘联系起来了?这和对偶性有关。
对偶性
对偶性的思想是:每当看到一个多维空间到数轴上的线性变换时,他都与空间中的唯一一个向量对应,也就是说使用线性变换和与这个向量点乘等价。这个向量也叫做线性变换的对偶向量。
当二维空间向一维空间映射时,如果在二维空间中等距分布的点在变换后还是等距分布的,那么这种变换就是线性的。
假设有一个线性变换A$\begin{bmatrix}1&-2\end{bmatrix}$和一个向量$\vec v=\begin{bmatrix}4\\3\end{bmatrix}$。
变换后的位置为$\begin{bmatrix}1&-2\end{bmatrix}\begin{bmatrix}4\\3\end{bmatrix}=4\cdot1+3\cdot-2=-2$,这个变换是一个二维空间向一维空间的变化,所以变换后的结果为一个坐标值。
我们可以看到线性变换的计算过程和向量的点积相同$\begin{bmatrix}1\\-2\end{bmatrix}\cdot\begin{bmatrix}4\\3\end{bmatrix}=4\cdot1+3\cdot-2=-2$,所以向量和一个线性变化有着微妙的联系。
假设有一个倾斜的数轴,上面有一个单位向量$\vec v$,对于任意一个向量它在数轴上的投影都是一个数字,这表示了一个二维向量到一位空间的一种线性变换,那么如何得到这个线性变化呢?
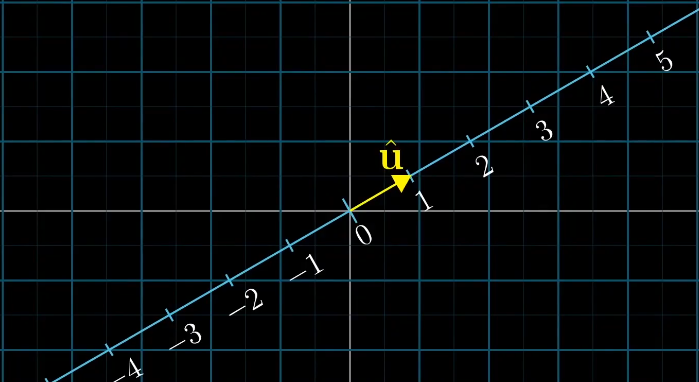
由之前的内容来说,我们可以观察基向量$\vec i$和$\vec j$的变化,从而得到对应的线性变化。
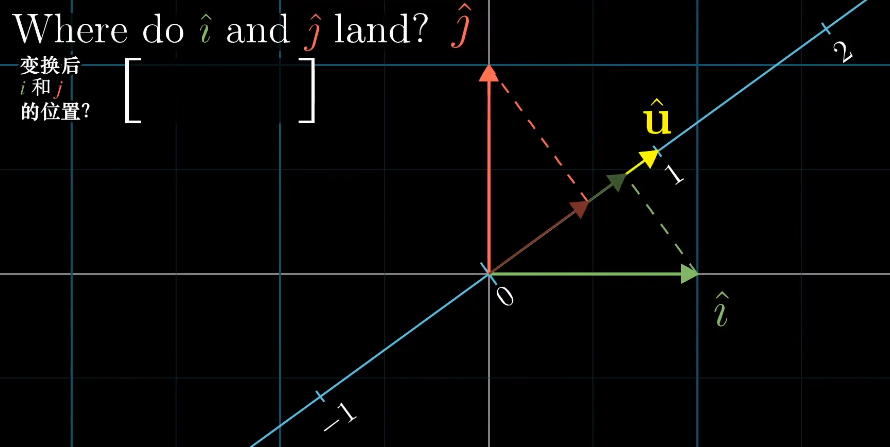
因为$\vec i$、$\vec j$、$\vec u$都是单位向量,根据对称性可以得到$\vec i$和$\vec j$在$\vec u$上的投影长度刚好是$\vec u$的坐标。
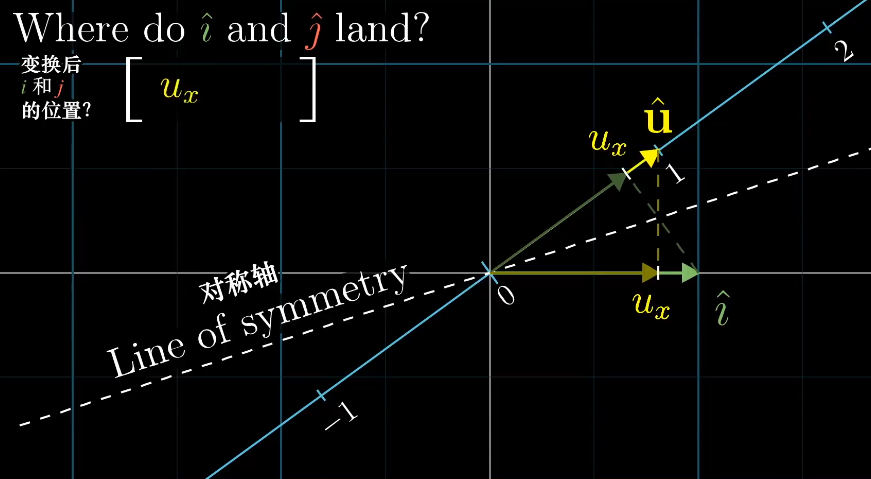
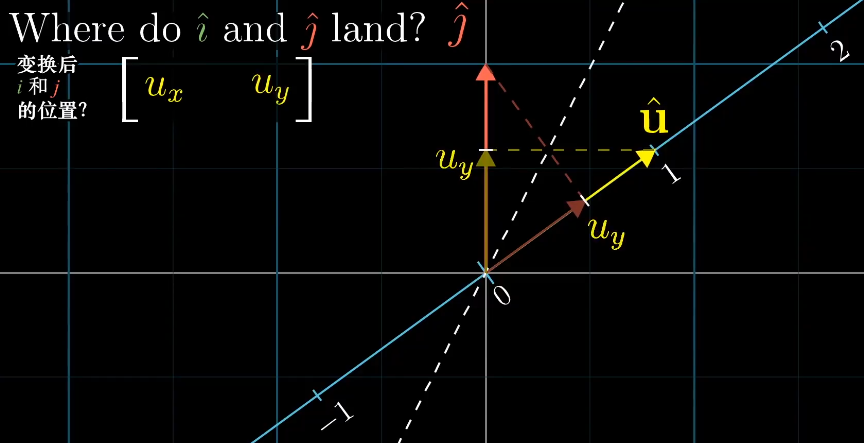
这样空间中的所有向量都可以通过线性变化$\begin{bmatrix}u_x&u_y \end{bmatrix}$得到,而这个计算过程刚好和单位向量的点积相同。
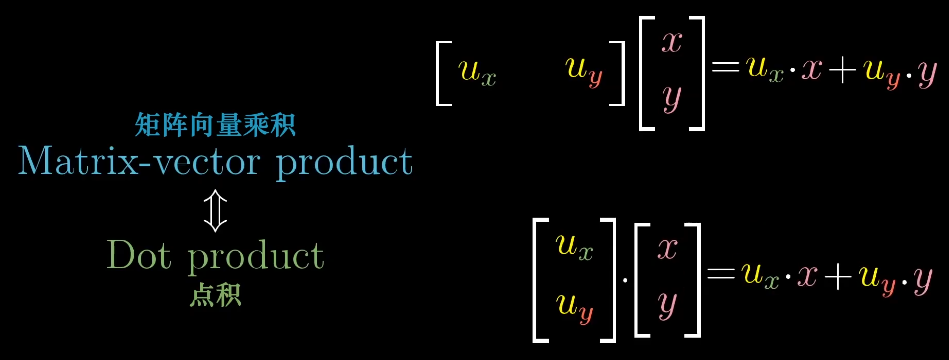
也就是为什么向量投影到直线的长度,刚好等于它与直线上单位向量的点积,对于非单位向量也是类似,只是将其扩大到对应倍数。
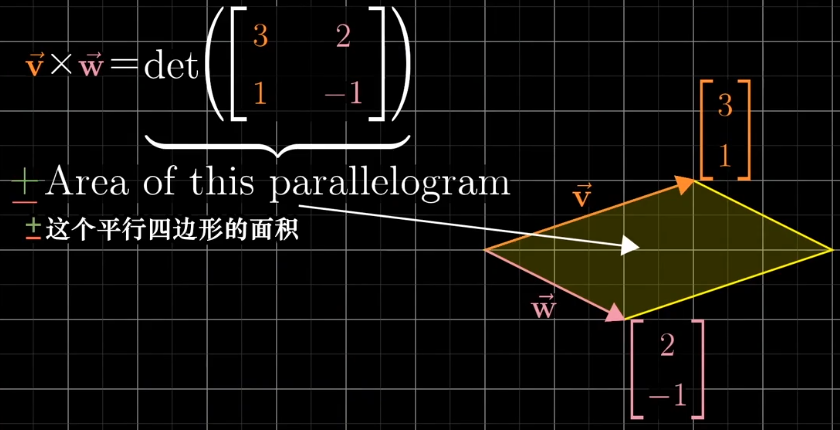
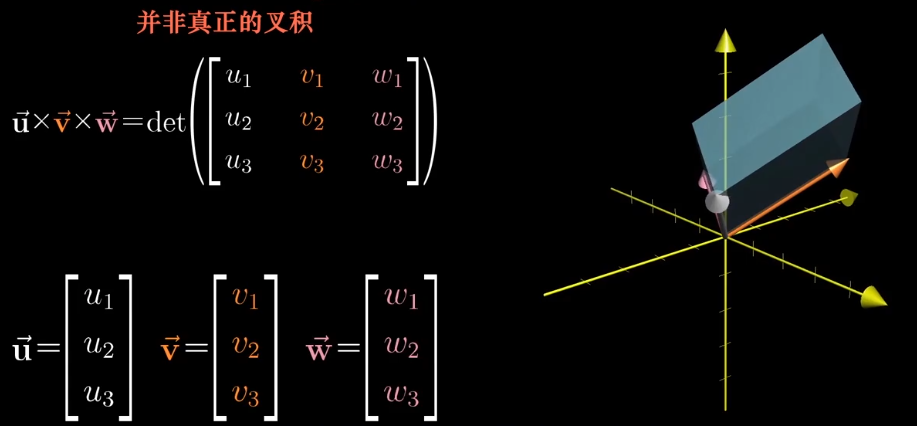
叉积
对于两个向量所围成的面积来说,可以使用行列式计算,将两个向量看作是变换后的基向量,这样通过行列式就可以得到变换后面积缩放的比例,因为基向量的单位为1,所以就得到了对应的面积。
考虑到正向,这个面积的值存在负值,这是参照基向量$\vec i$和$\vec j$的相对位置来说的。

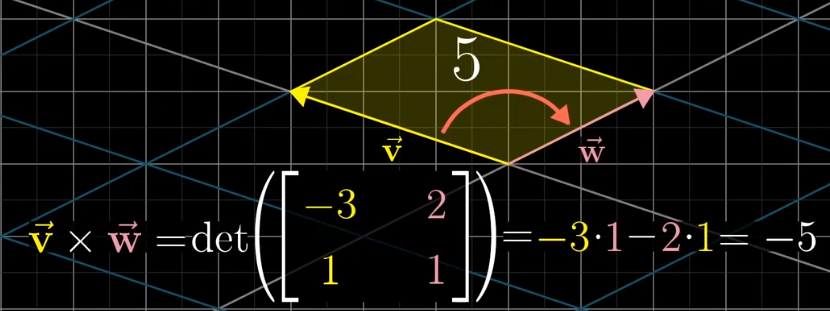
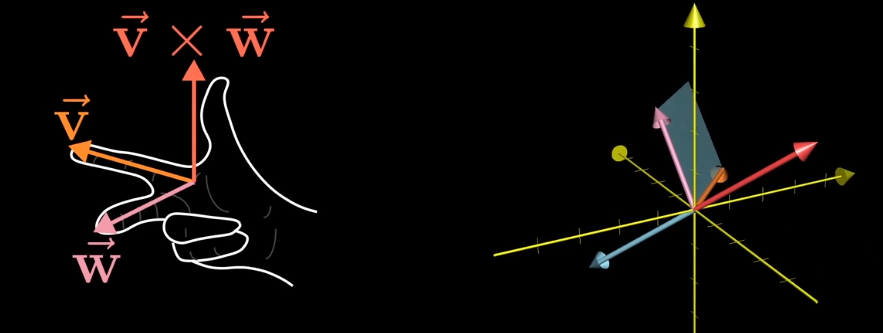
真正的叉积是通过两个三维向量$\vec v$和$\vec w$,生成一个新的三维向量$\vec u$,这个向量垂直于向量$\vec v$和$\vec w$所在的平面,长度等于它们围成的面积。
叉积的反向可以通过右手定则判断:
叉积的计算方法:
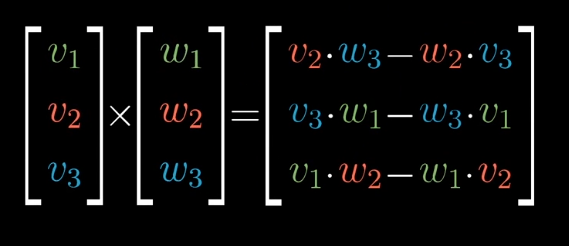

线性代数看叉积
参考二维向量的叉积计算:
三维的可以写成类似的形式,但是他并是真正的叉积,不过和真正的叉积已经很接近了。
我可以构造一个函数,它可以把一个三维空间映射到一维空间上。
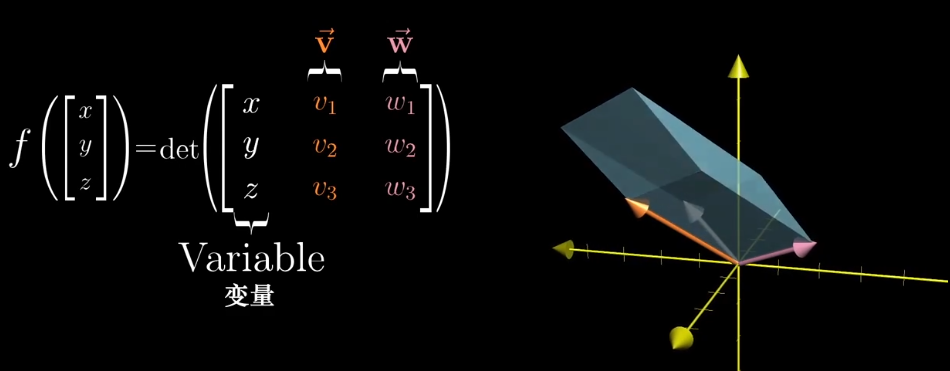
右侧行列式是线性的,所以我们可以找到一个线性变换代替这个函数。
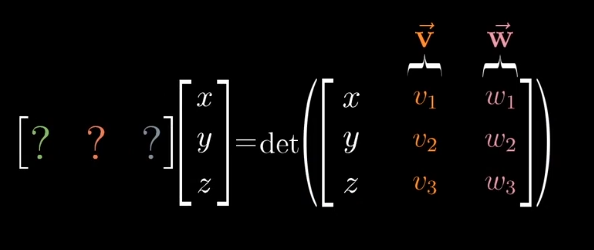
根据对偶性的思想,从多维空间到一维空间的线性变换,等于与对应向量的点积,这个特殊的向量$\vec p$就是我们要找的向量。

从数值计算上:
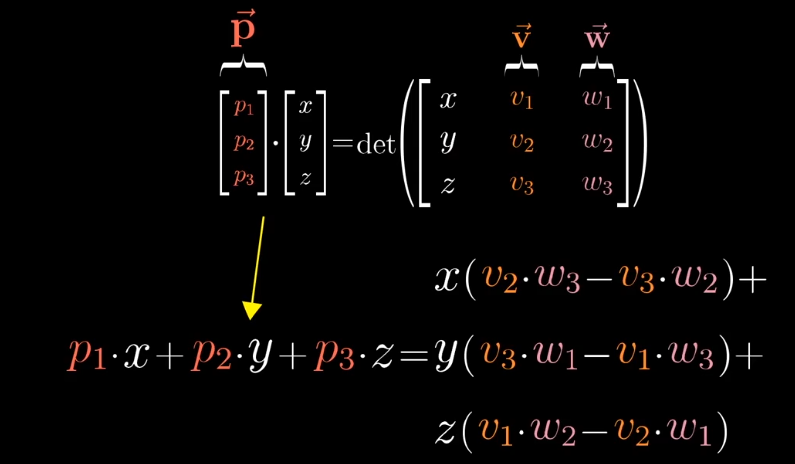
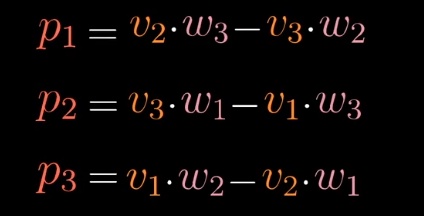
向量$\vec p$的计算结果刚好和叉积计算的结果相同。
从几何意义:
当向量$\vec p$和向量$\begin{bmatrix}x\y\z \end{bmatrix}$点乘时,得到一个$\begin{bmatrix}x\y\z \end{bmatrix}$与$\vec v$与$\vec w$确定的平行六面体的有向体积,什么样的向量满足这个性质呢?
点积的几何解释是,其他向量在$\vec p$上的投影的长度乘以$\vec p$的长度。
对于平行六面体的体积来说,它等于$\vec v$和$\vec w$所确定的面积乘以$\begin{bmatrix}x\y\z \end{bmatrix}$在垂线上的投影。
那么$\vec p$要想满足这一要求,那么它就刚好符合,长度等于$\vec v,\vec w$所围成的面积,且刚好垂直这个平面。
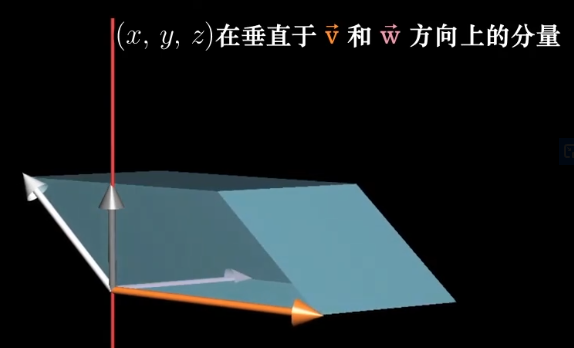
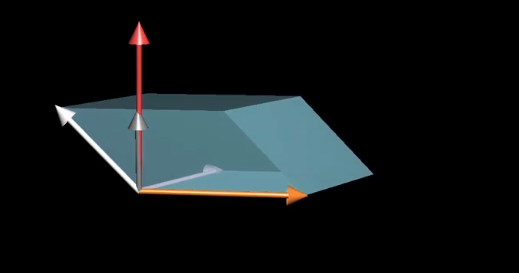
基变换
标准坐标系的基向量为$\vec {i}: \begin{bmatrix}1\\0 \end{bmatrix}$和$\vec {j}: \begin{bmatrix}0\\1 \end{bmatrix}$,假如詹妮弗有另一个坐标系:她的基向量为$\vec i \begin{bmatrix}2\\1 \end{bmatrix}$和$\vec j \begin{bmatrix}-1\\1 \end{bmatrix}$。
对于同一个点$\begin{bmatrix}3\\2 \end{bmatrix}$来说他们所表示的形式不同,在詹妮弗的坐标系中表示为$\begin{bmatrix}\frac{5}{3}\\\frac{1}{3} \end{bmatrix}$。
从标准坐标到詹尼佛的坐标系,我能可以得到一个线性变换$A:\begin{bmatrix}2&-1\\1&1 \end{bmatrix}$。
如果想知道詹妮弗的坐标系中点$\begin{bmatrix}3\\2 \end{bmatrix}$在标准坐标系的位置,可以通过$\begin{bmatrix}2&-1\\1&1 \end{bmatrix}\begin{bmatrix}3\\2 \end{bmatrix}$得到。
如果想知道标准坐标系中点$\begin{bmatrix}3\\2 \end{bmatrix}$在詹妮弗坐标系的位置,可以通过$\begin{bmatrix}2&-1\\1&1 \end{bmatrix}^{-1}\begin{bmatrix}3\\2 \end{bmatrix}$得到。
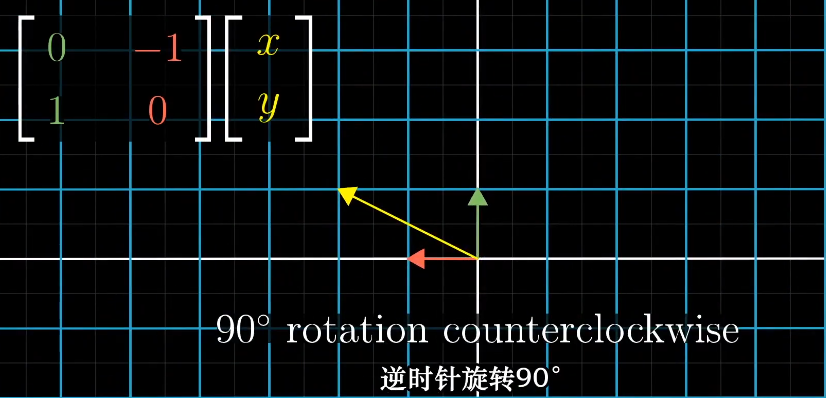
具体的例子,90°旋转。
在标准坐标系可以跟踪基向量的变化来体现:

在詹妮弗的坐标系中如何表示旋转呢?首先将向量转换为标准坐标系的表示,然后左旋,最后再转换为詹妮弗的表示。
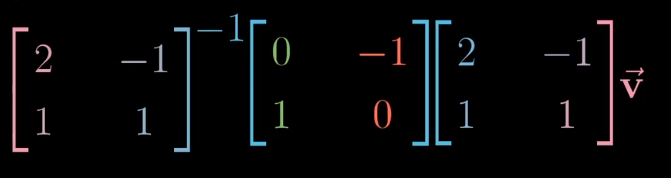
所以我们可以得到对于詹妮弗坐标系的左旋线性变化的表示:
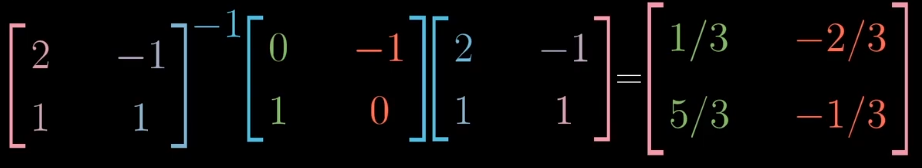
所以表达式$A^{-1}MA$表示一种数学上的转移作用,$M$表示一种线性变换,$A$和$A^{-1}$表示坐标系的转换。
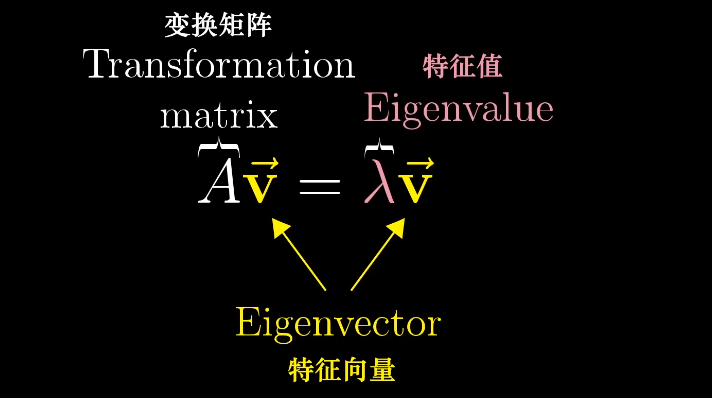
特征向量与特征值
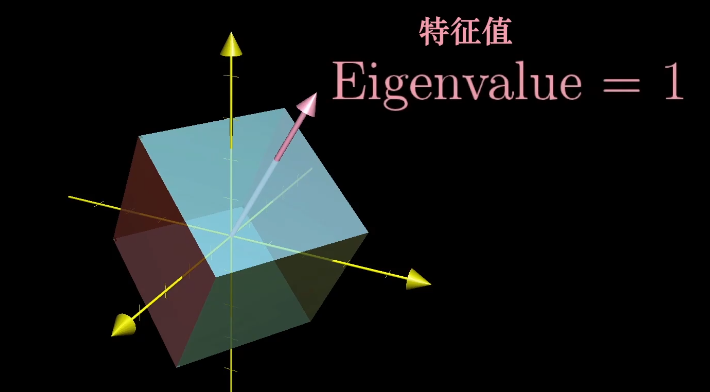
对于一些线性变化来说,存在一些向量在变换前后留在了张成的空间里,只是拉伸或收缩了一定比例,这些向量称为特征向量,拉伸收缩的比例称为特征值。
一个三维空间的旋转,如果能找到特征值为1的特征向量,那么它就是旋转轴,因为旋转并不进行缩放,且旋转轴在线性变换中保持不变。
特征向量的求解
特征向量的概念,等号左侧表示矩阵向量的乘积,等号右侧表示向量数乘,可以将右侧重写为某个向量的乘积,$\vec I$为单位向量。
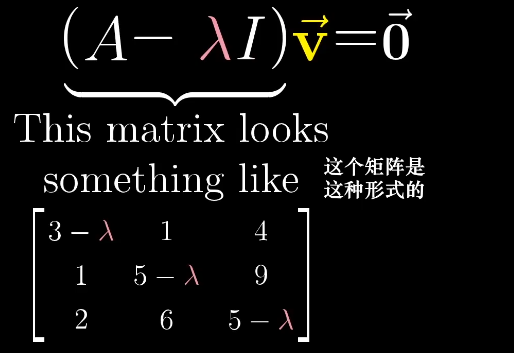
求解等式,就是使左侧的行列式det为0,$\lambda$就是特征值。
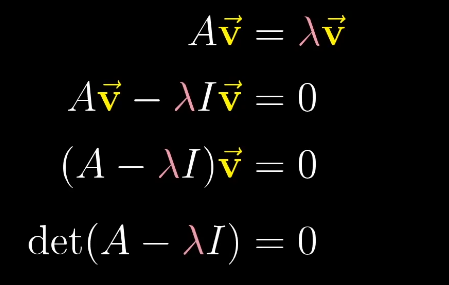
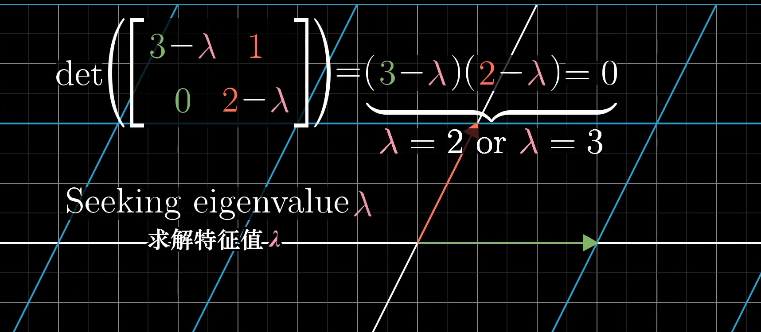
求解$\lambda$对应的特征向量时,即求解满足$(A-\lambda I)\vec{X}=0$的所有向量$\vec{X}$。
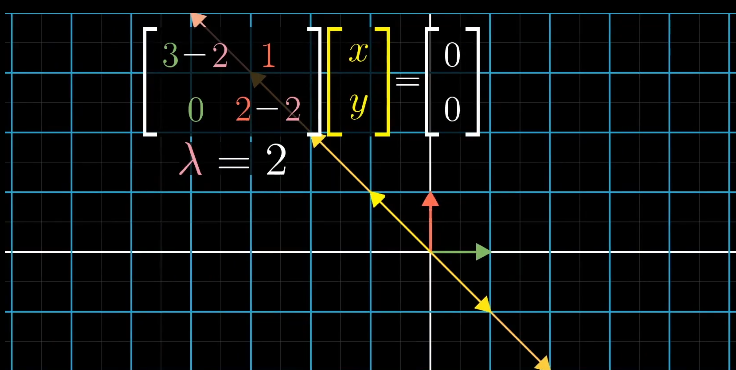
对应原始矩阵上所有落在$\begin{bmatrix} -1 \ 1 \end{bmatrix}$的向量被拉伸了2倍。

二维线性变换不一定存在特征向量,例如左旋90°,每个想都都发生了旋转,离开了张成空间。如果强行计算,会得到两个虚根:
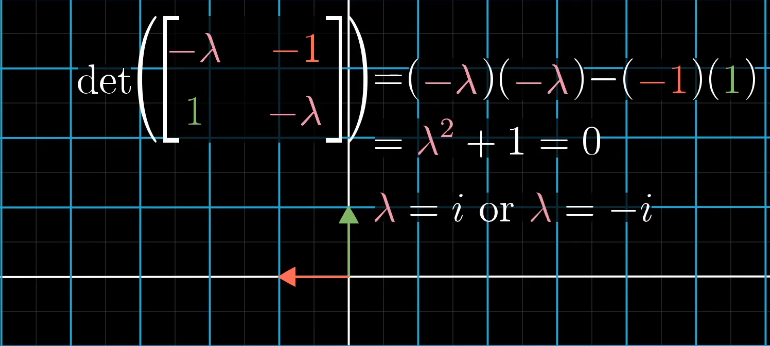
剪切变换的特征向量分布在x轴:

只有一个特征值,但是特征向量不一定只在一条直线上:
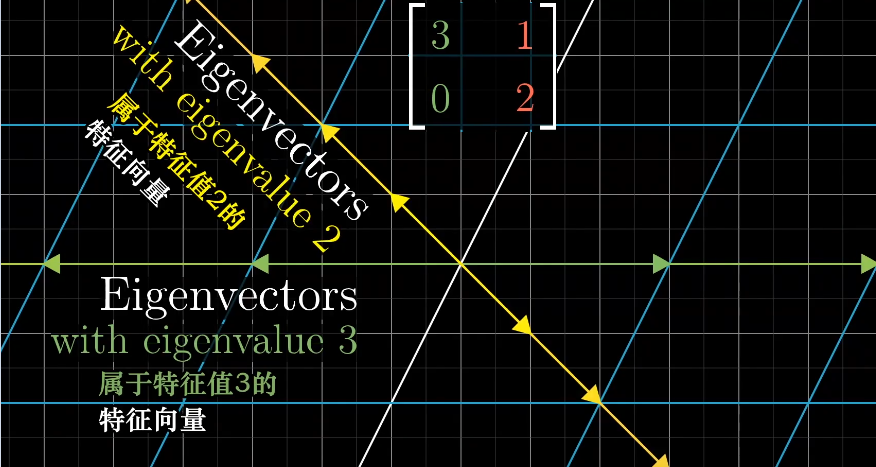
特征基
一组基向量构成的集合被称为一组特征基
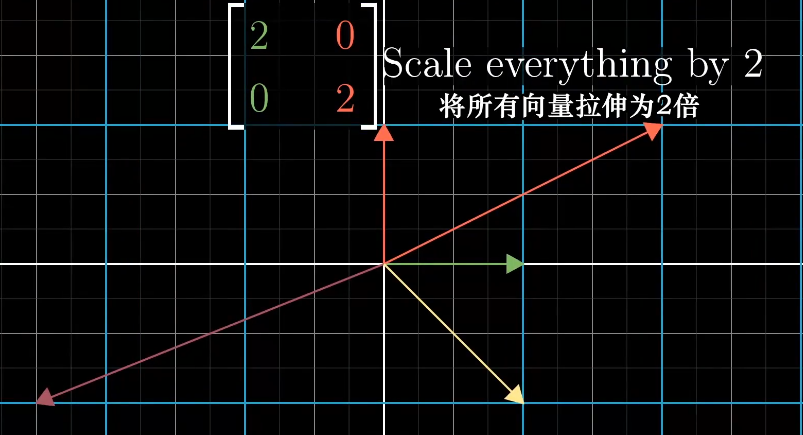
如果特征向量是基向量,它对应的矩阵是一个对角矩阵,矩阵的对角元是它们所属的特征值。

对角矩阵在求幂次时更方便求解,对应的幂次就是对角元的幂次。
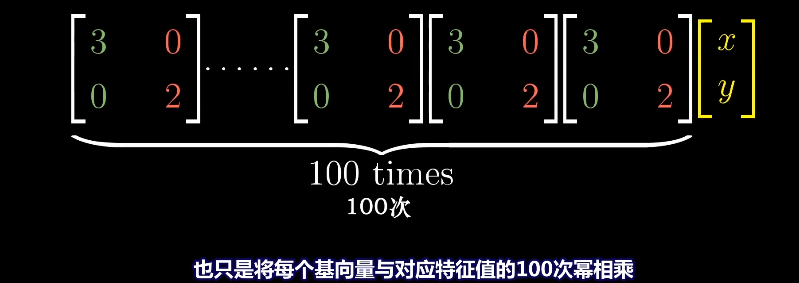
而对于非对角矩阵的幂次求解就非常麻烦。
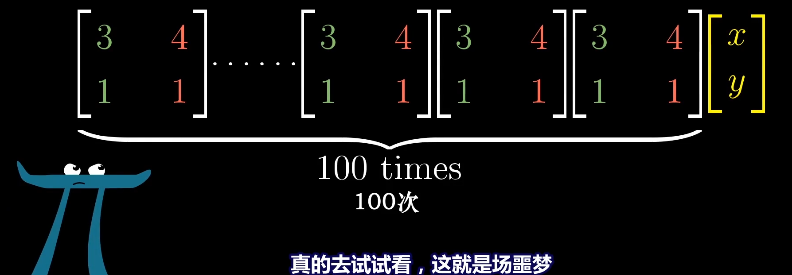
实际遇到对角矩阵的概率很低,但是我们可以通过基坐标变换来得到对角矩阵,前提有足够多的特征向量且可以张成整个空间,例如剪切变化就不行,应为它只有一个特征向量,无法进行坐标变换。
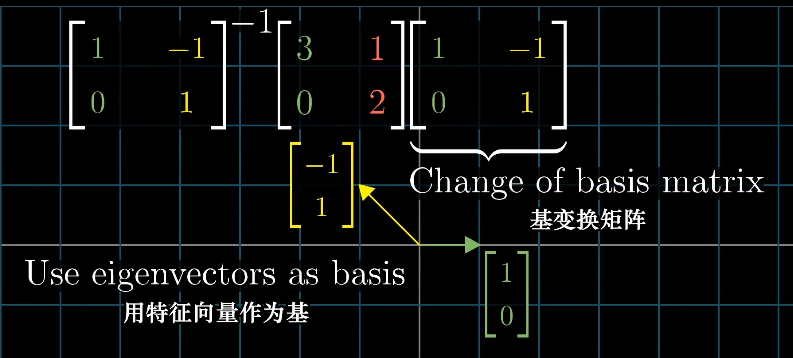
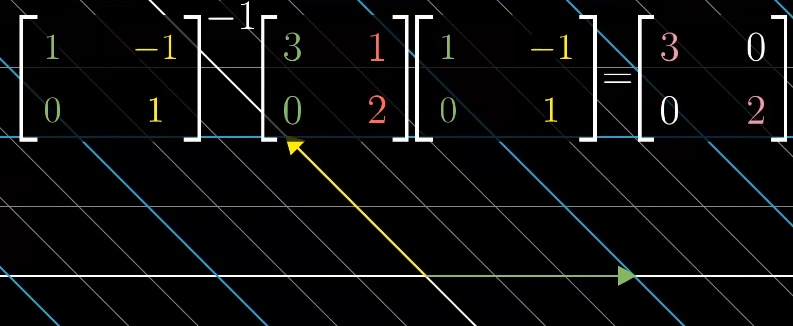

求解特征值:
$\begin{bmatrix}-\lambda&1\1&1-\lambda \end{bmatrix}\vec{X}=0$
抽象向量空间
线性的严格定义是:可加性和成比例性。

和函数的求导类似,求导具有可加性和成比例性。
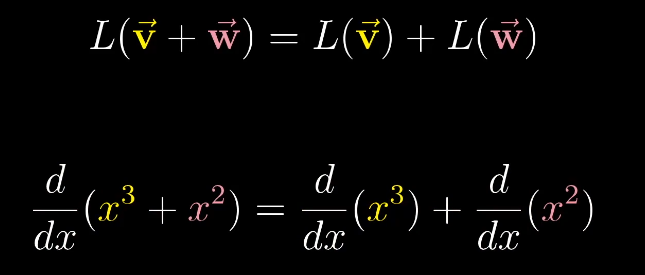
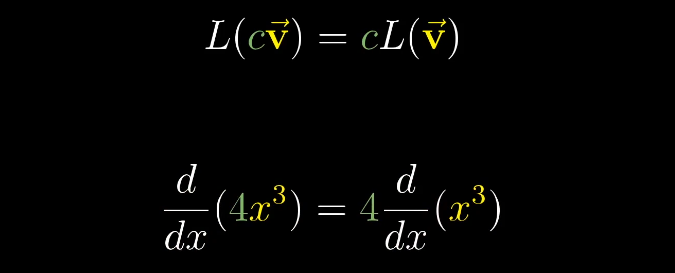
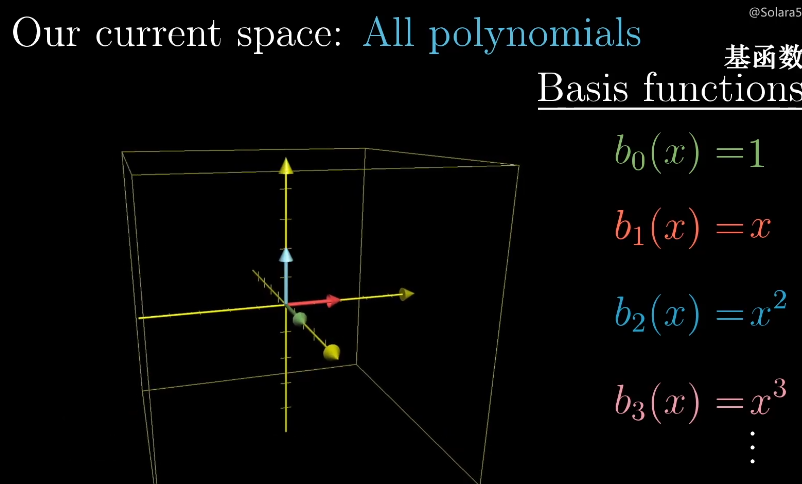
对于多项式的求导,我们也可以看成是矩阵的形式,将x的不同次幂看成基函数,这和多维空间的基向量类似。
因为求导的可加性和成比例行,我们可以分别对每个基向量求导,从而得到左侧的矩阵。
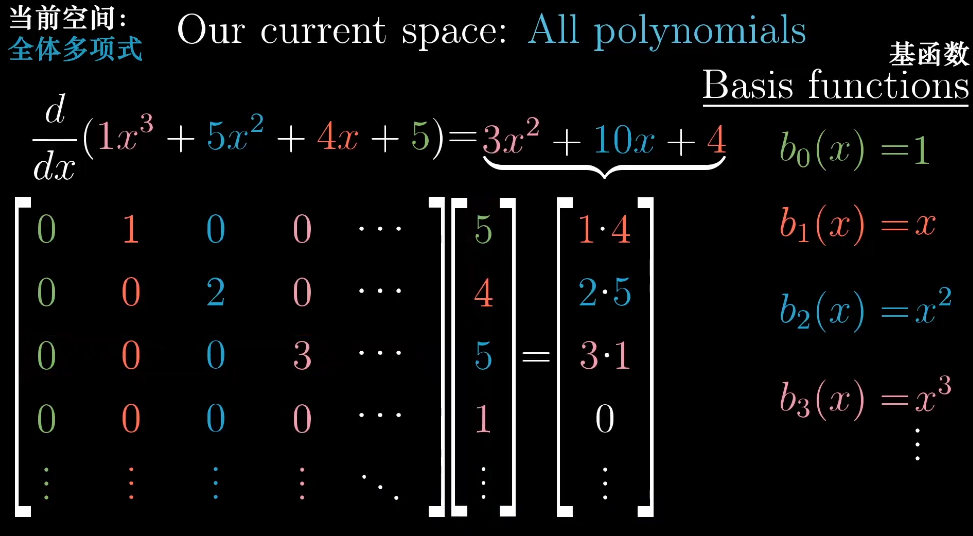
数学中有很多类似向量的事物,只要处理的对象具有数乘和相加的概念,都可以运行向量的基本性质。
对于发明向量的数学家来说,他不用考虑其他所有类似的向量,他只需要给出向量数乘和加法必须遵守的规则即定理,那么所有满足这些定理的对象,就可以使用向量所拥有的性质。

课后作业及答案:https://github.com/Sanzona/ML-homework
监督学习
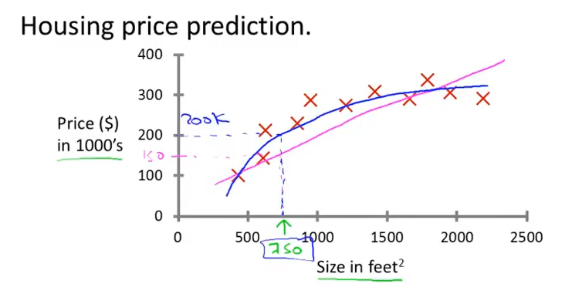
监督学习是已经知道数据的label,例如预测房价问题,给出了房子的面积和价格。
回归问题是预测连续值的输出,例如预测房价。
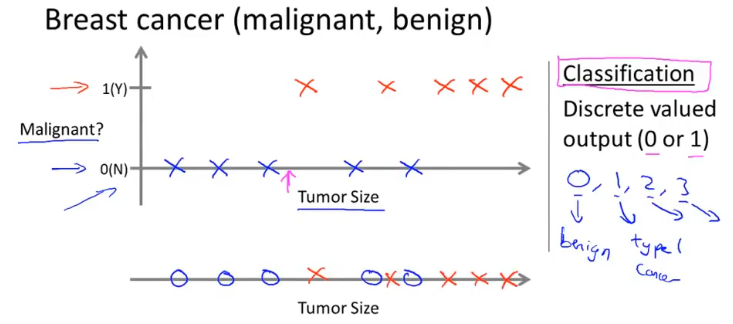
分类问题是预测离散值输出,例如判断肿瘤是良性还是恶性。
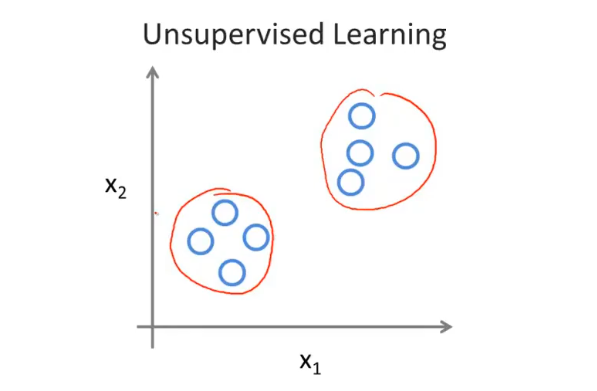
无监督学习
无监督学习是不知道数据具体的含义,比如给定一些数据但不知道它们具体的信息,对于分类问题无监督学习可以得到多个不同的聚类,从而实现预测的功能。
线性回归
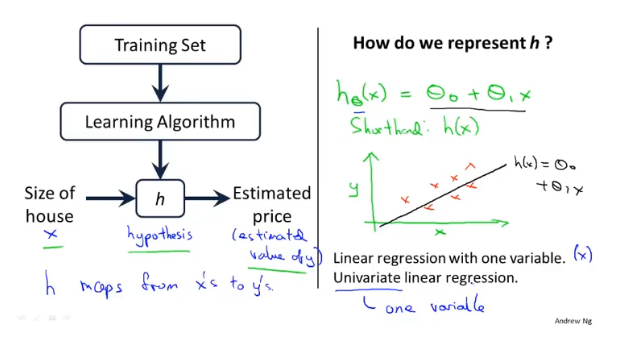
线性回归是拟合一条线,将训练数据尽可能分布到线上。另外还有多变量的线性回归称为多元线性回归。
代价函数
cost function,一般使用最小均方差来评估参数的好坏。

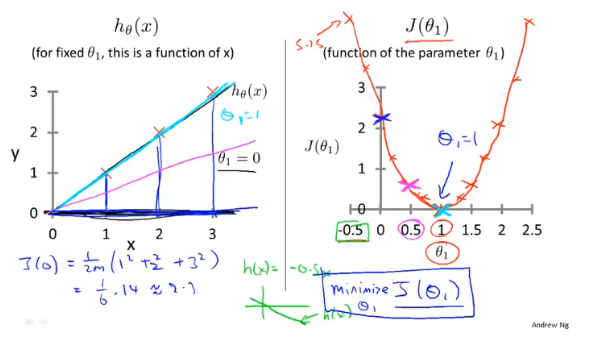
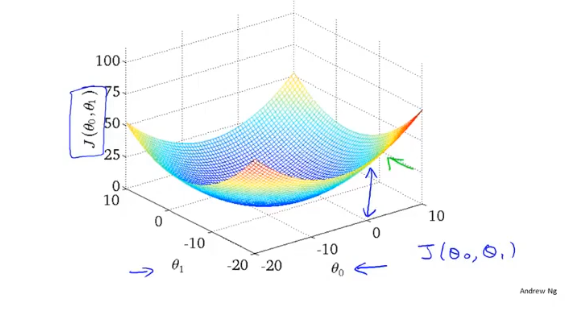
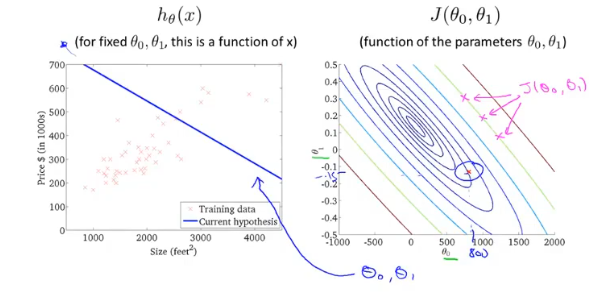
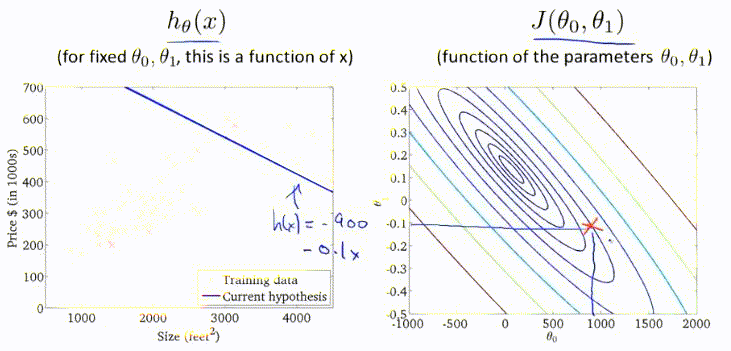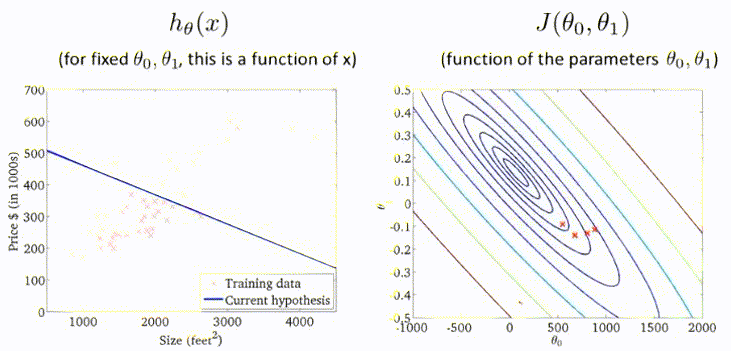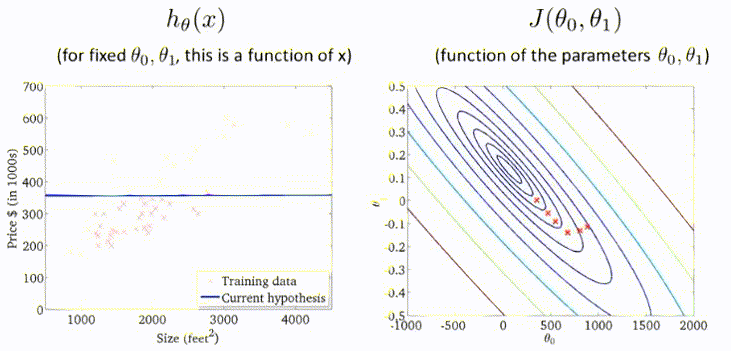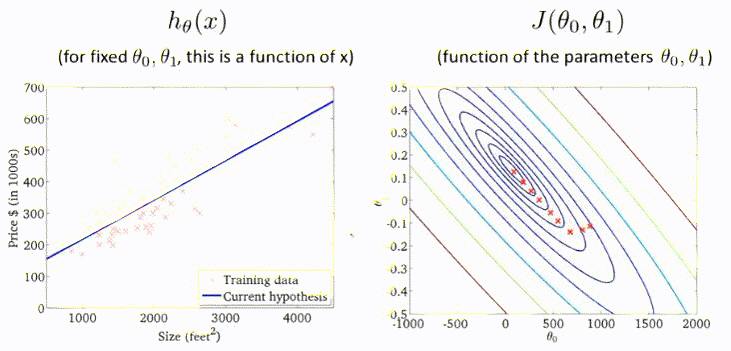
梯度下降
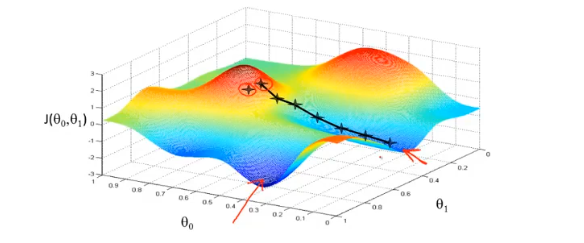
梯度下降,首先为每个参数赋一个初值,通过代价函数的梯度,然后不断地调整参数,最终得到一个局部最优解。初值的不同可能会得到两个不同的结果,即梯度下降不一定得到全局最优解。
梯度下降在具体的执行时,每一次更新需要同时更新所有的参数。

梯度下降公式中有两个部分,学习率和偏导数。
偏导数,用来计算当前参数对应代价函数的斜率,导数为正则$\theta$减小,导数为负则$\theta$增大,通过这样的方式可以使整体向$\theta=0$收敛。
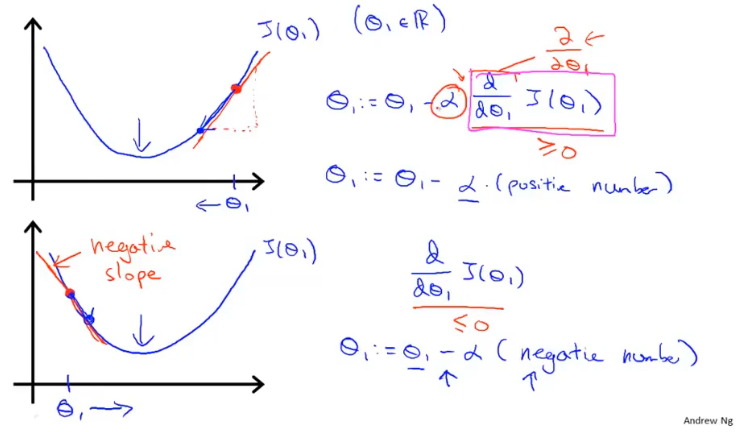
$\alpha$用来描述学习率,即每次参数更新的步长。$\alpha$的大小不好确定,如果太小则需要很多步才能收敛,如果太大最后可能不会收敛甚至可能发散。
当$\theta$处于局部最优解时,$\theta$的值将不再更新,因为偏导为0。
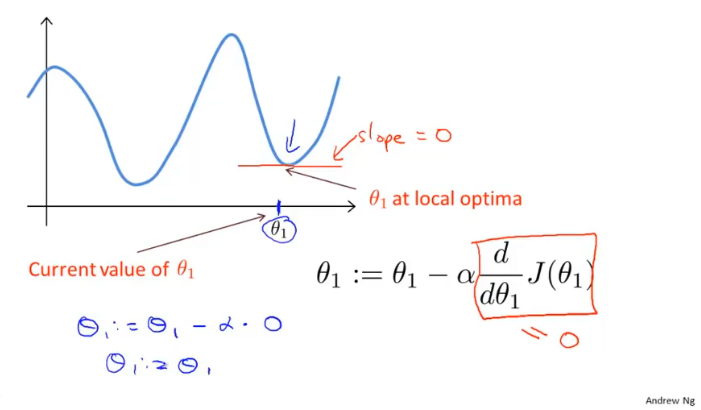
这也说明了如果学习率$\alpha$不改变,参数也可能收敛,假设偏导$> 0$,因为偏导一直在向在减小,所以每次的步长也会慢慢减小,所以$\alpha$不需要额外的减小。
单元梯度下降
梯度下降每次更新的都需要进行偏导计算,这个偏导对应线性回归的代价函数。

对代价函数求导的结果为:
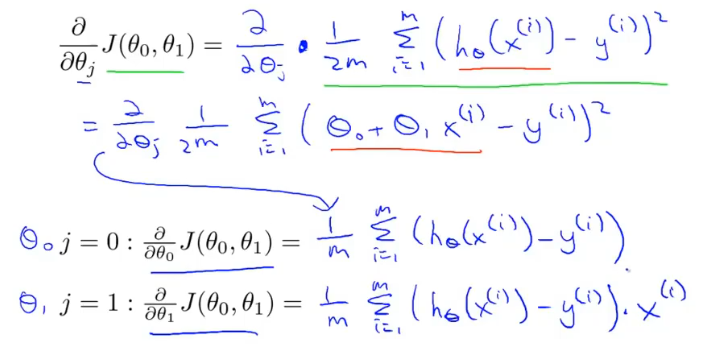
梯度下降的过程容易出现局部最优解:
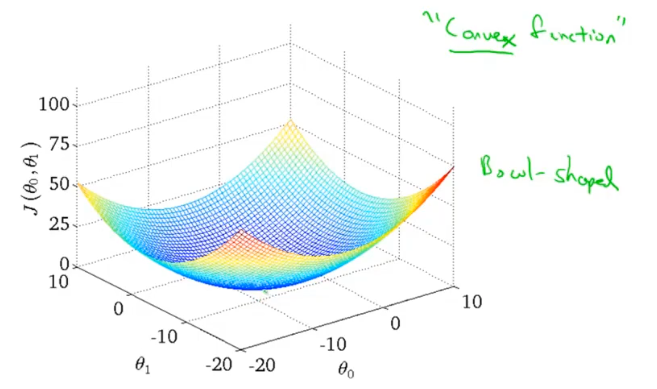
但是线性回归的代价函数,往往是一个凸函数。它总能收敛到全局最优。
梯度下降过程的动图展示:
多元梯度下降
通常问题都会涉及到多个变量,例如房屋价格预测就包括,面积、房间个数、楼层、价格等

因此代价函数就不再只包含一个变量,为了统一可以对常量引入变量$x_0=1$。
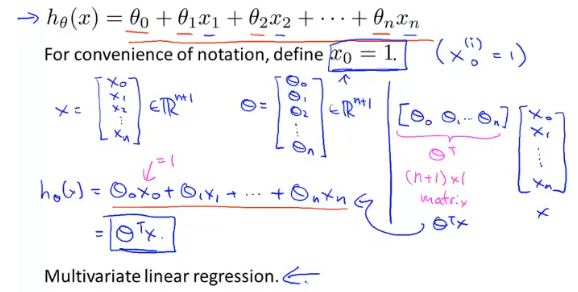
虽然参数的个数增多,但是对每个参数求偏导时和单个参数类似。

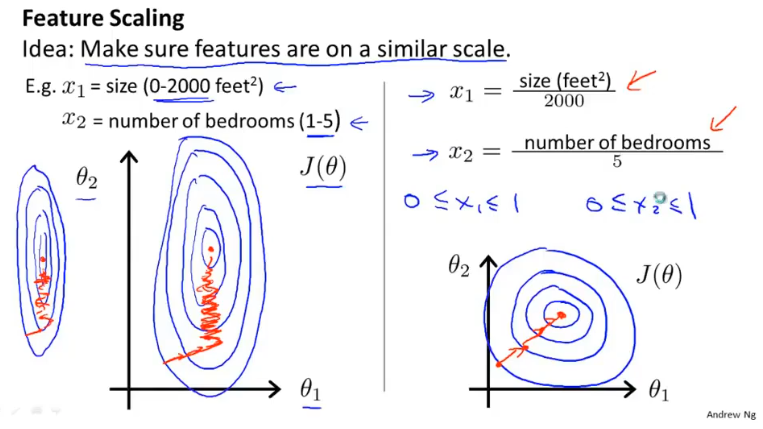
特征缩放
多个变量的度量不同,数字之间相差的大小也不同,如果可以将所有的特征变量缩放到大致相同范围,这样会减少梯度算法的迭代。
特征缩放不一定非要落到[-1,1]之间,只要数据足够接近就可以。
$X_i = \frac{X_i-\mu}{\sigma}$,$\mu$表示平均值,$\sigma$表示标准差。


缩放后的还原
经过线性回归得到的参数$\theta’$,对应着缩放后的数据,如何得到缩放前的参数$\theta$?
学习率
学习率$\alpha$的大小会影响梯度算法的执行,太大可能会导致算法不收敛,太小会增加迭代的次数。
可以画出每次迭代的$J(\theta)$的变化,来判断当前算法执行的情况,然后选择合适的学习率。(调参开始…)
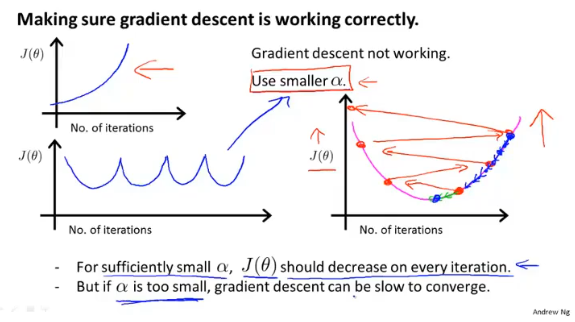

Batch梯度下降:每一步梯度下降,都需要遍历整个训练集样本。
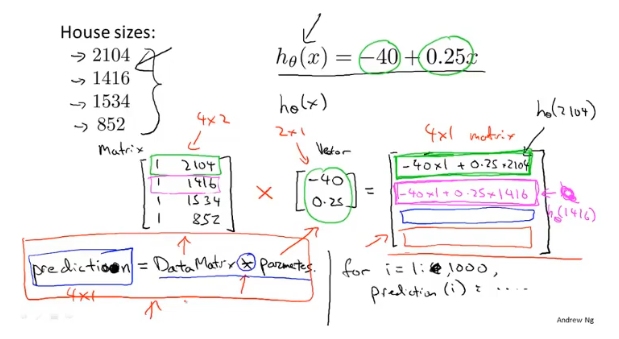
矩阵和向量
一些数学计算转化为矩阵的形式,可以简化代码书写、提高效率、代码更容易理解。
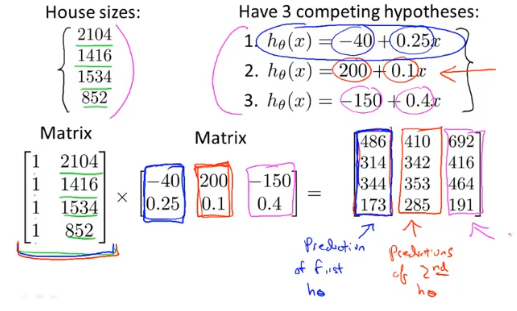
矩阵乘法不满足交换律:

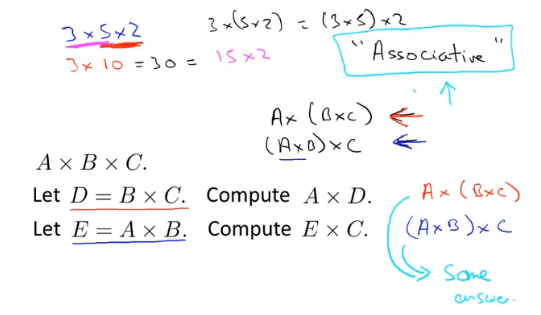
矩阵乘法满足结合律:
单位矩阵:

矩阵的逆:
- 首先是方阵
- 不是所有的矩阵都有逆

转置矩阵:
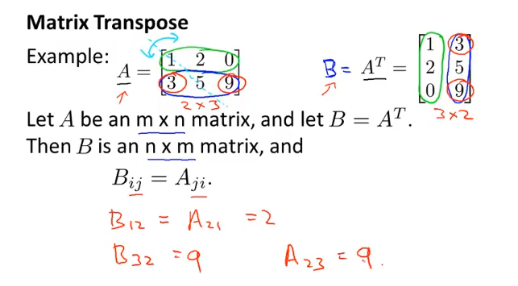
正则方程
偏导等于0对应线性方程的最小值:
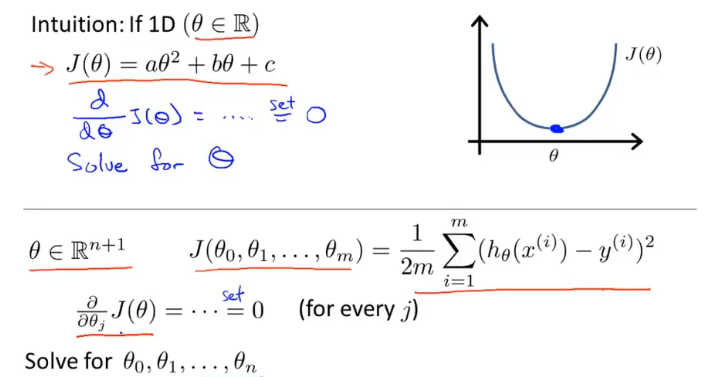
利用线性代数的方法直接求解$\theta$。
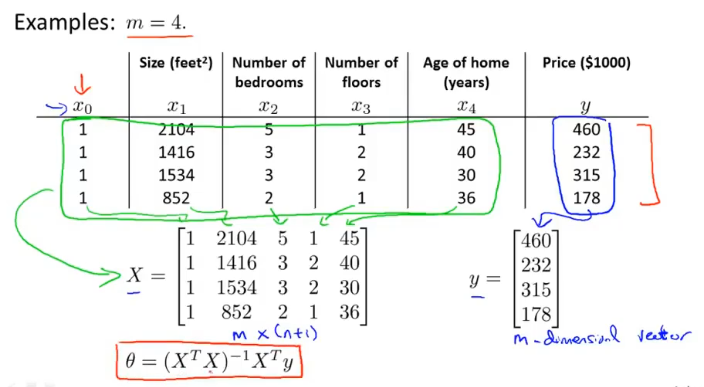
$\theta$的推导可以根据等式$X\theta=y$得到,$X^TX$的目的是将矩阵转化为方阵,因为求矩阵的逆的前提是方阵。
矩阵可能存在 不可逆的情况,这时可是删除一些不必要的特征,或使用正则化。
梯度下降和正则方程的优缺点:

逻辑回归
Logistic Regression
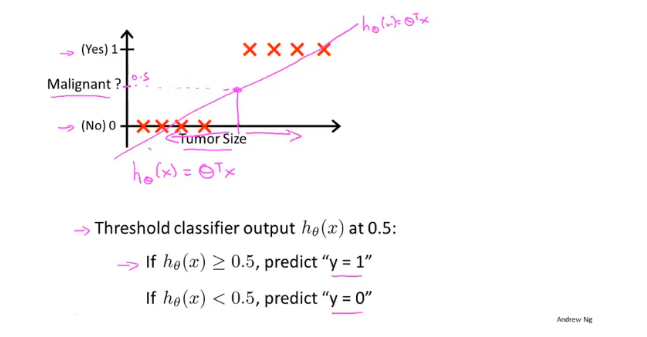
逻辑回归用于解决分类的问题,如果使用线性回归可能会造成很大的误差;假如样本的标签值为0、1,线性回归输出值是连续的存在>1和小于0的情况,不符合实际。
如果对于一个均匀的数据,使用线性回归,选取0.5作为分界线,可能会得到一个比较准确的模型,但是如果数据不太均匀就会存在很大的误差。
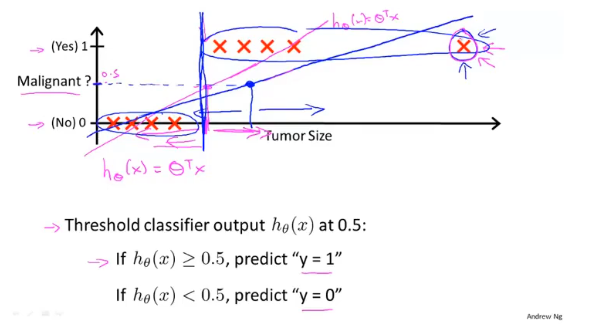
激活函数
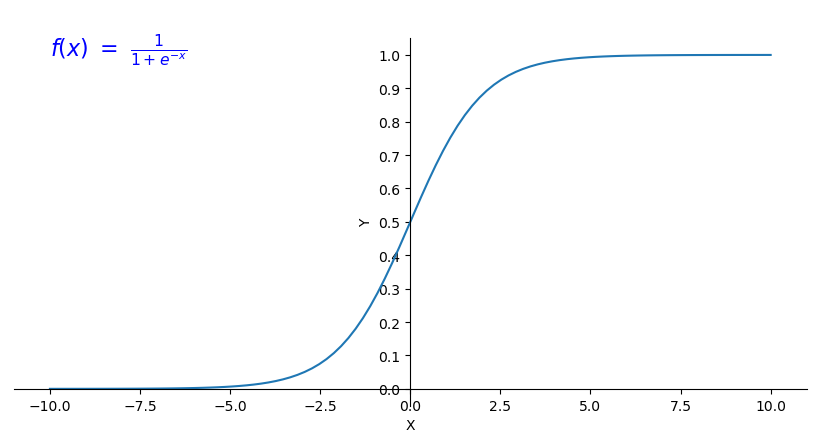
激活函数的y值分布在[0,1]内,对于分类问题,我们可以使用激活函数的值来表示满足特征的概率。

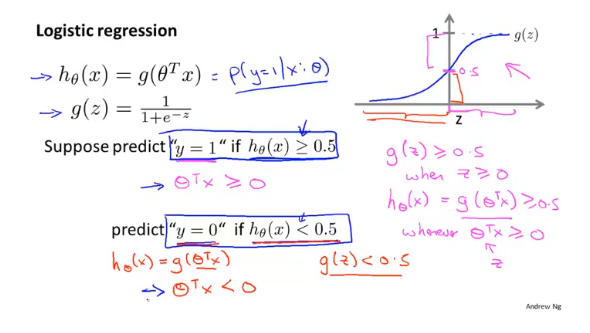
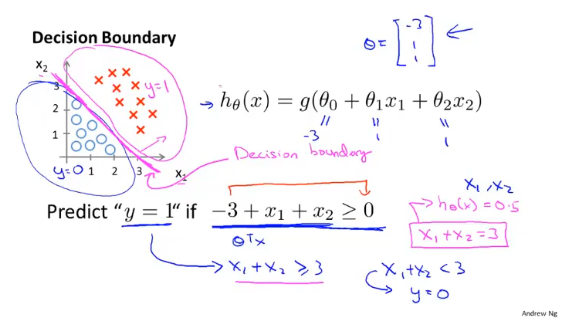
决策界限
决策边界是假设函数的一个属性,取决于函数的参数,而不是数据集。
假设以x=0,y=0.5作为判断的界限,当$\theta^Tx >=0.5$,预测$y=1$;$\theta^Tx <0.5$,预测$y=0$。
[代码示例](https://github.com/Sanzona/ML-homework/blob/main/ex2-logistic regression/ex2-regularized logistic regression.ipynb)

代价函数
对于函数$f(x)=\frac{1}{1+e^{-x}}$,如果使用类似线性回归的代价函数$\Sigma(h(x)-y)^2$,将得到一个非凸函数,这样就不能使用梯度下降的方法求解全局最优解。
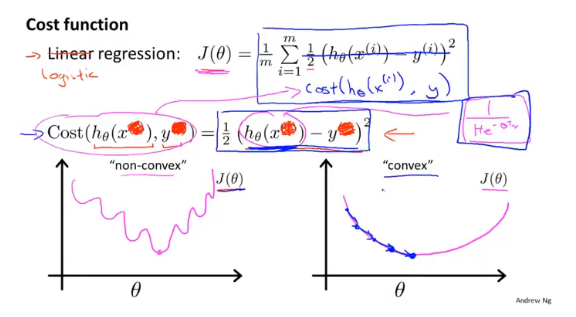
逻辑回归一般使用对数函数作为代价函数:
首先对于分类函数来说,他的输出值范围为[0,1],得到的对数图像如下:
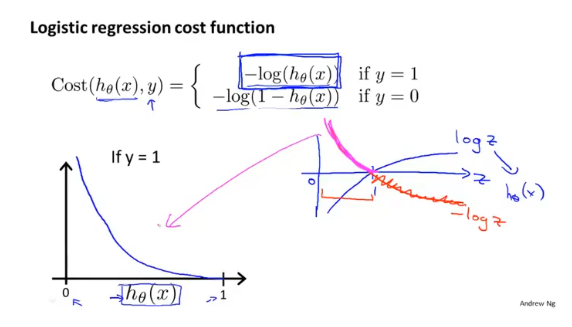
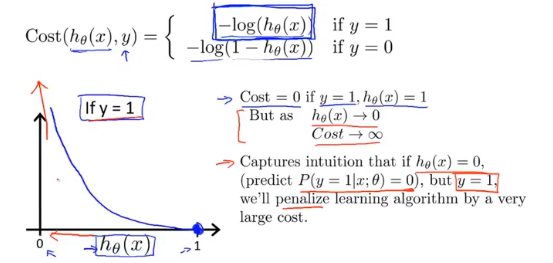
当评估模型参数对y=1(恶性肿瘤)进行预测的好坏时,如果实际为恶性,预测值也为1(恶性),此时的代价为0;如果实际为恶性,预测为0(良性),此时的代价为$+\infty$,这时代价函数就很好的评估了参数$\theta$的表现。
同样对于y=0(良性肿瘤)的代价函数为:
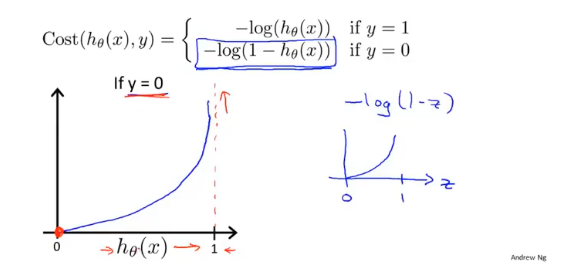
y的取值只有0、1,可以将上面两个函数合成一个,评估当前参数的$J(\theta)$为:

梯度下降
在确定代价函数之后的任务是,如何最小化代价函数,因为代价函数是凸的,所以可以使用梯度下降求解。


虽然求偏导之后,$\theta$更新的形式和线性回归类似,但是他们本质不同,因为$h_\theta(x)$完全不一样。

多元分类
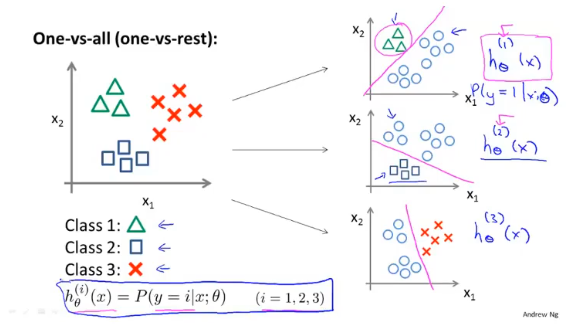
对每个特征单独训练,在做预测的时候,取三个分类器结果最大的。

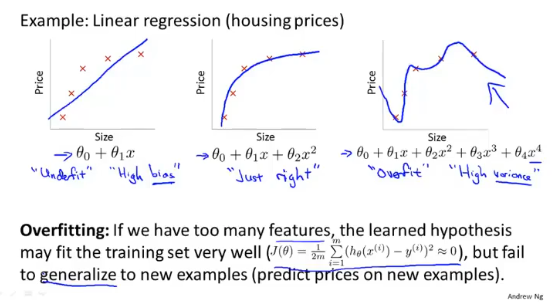
过拟合
存在多个特征,但是数据很少,或者模型函数不合理,都会出现过拟合的现象。过拟合可能对样本数能够很好的解释,但是无法正确的预测新数据。
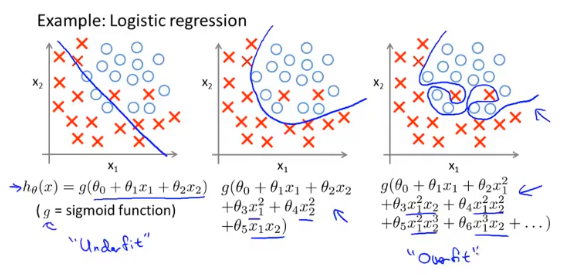
正则化
解决过拟合的方法:

正则化处理过拟合问题:
在代价函数中加入正则项,通过lambda的来平衡拟合程度和参数的大小,$\theta$约大越容易出现过拟合的现象。
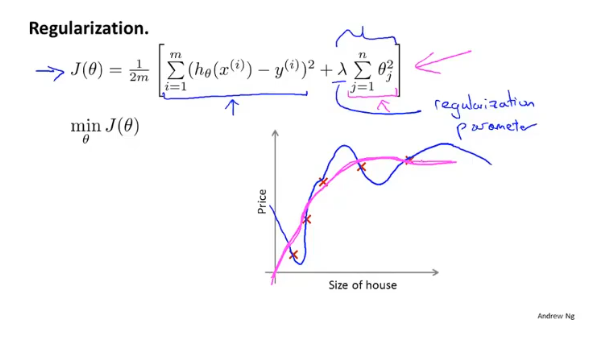
如果lambda过大,导致$\theta \approx 0$,那么最终只剩下下$\theta_0$,图像将变成一个直线。


模型评估
训练、测试集
将数据集分为训练集和测试集,训练集得到参数$\theta$,然后使用测试集的数据对参数$\theta$进行评估,即计算误差。
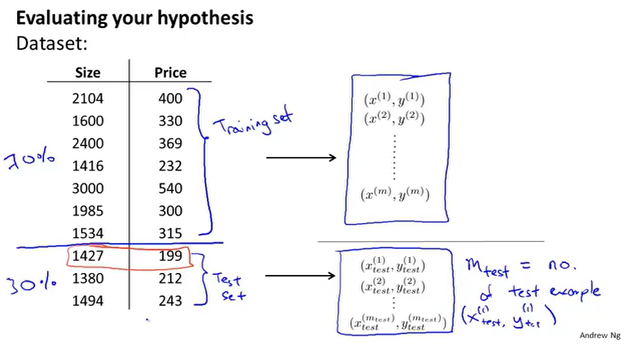
线性回归问题的评估:

逻辑回归问题的评估:

训练、验证、测试集
首先用训练集得到一个最优的参数$\theta$,然后用测试集进行评估误差。通过这样的方式可以在众多模型中选择一个理想的模型。
但是这样做并不能评估模型的泛化能力,通过测试集评估选择的模型,可能刚好适合测试集的数据,并不能说明它对其他数据的预测能力,这时就引入了验证集。

将数据集分为:训练集、验证集、测试集。
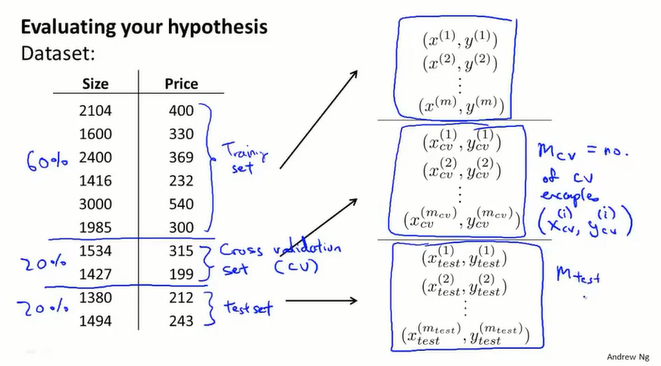
对于每个集合都可以计算相应的误差。

这样在选择模型的时候,可以先使用测试集得到每个模型的$\theta$,然后使用验证集评估得到误差最小的模型,最后使用测试集评估他的泛化能力。

偏差、方差
当多项式次数增大时,训练集的误差慢慢减小,因为多项式次数越高,图像拟合的就越准确。但是验证集不同,它的趋势是先减少后增大,这分别对应着欠拟合和过拟合。
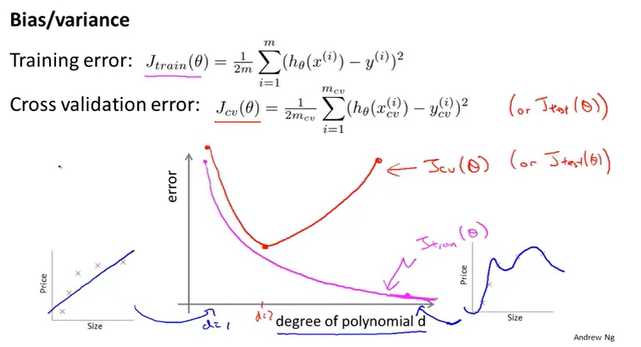
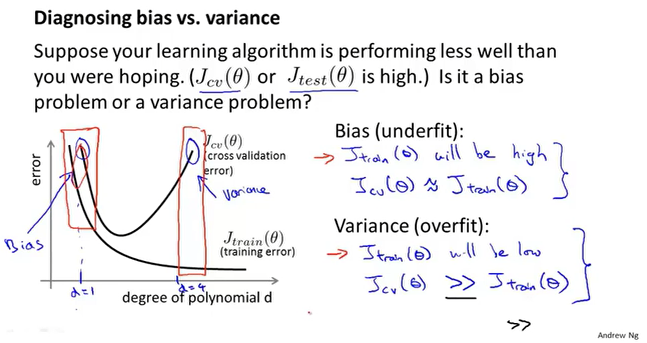
那么我们可以根据误差的不同表现来区分偏差和方差。
高偏差:训练误差和验证误差都很大。
高方差:训练误差小,验证误差大。
正则化
通过引入$\lambda$来平衡多形式的权重。
当$\lambda$太大,参数$\theta \approx0$,模型近似直线,即欠拟合。当$\lambda$太小,就会出现过拟合。
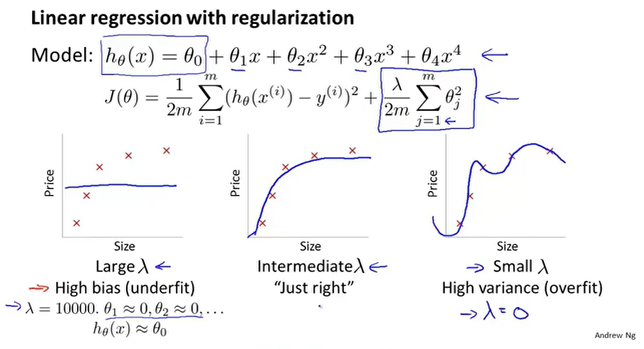
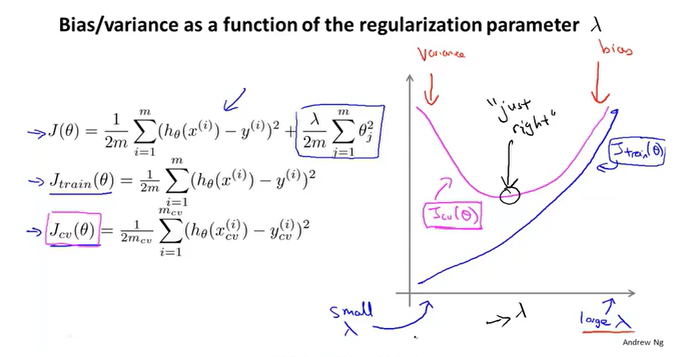
学习曲线
随着数据量的增加,$J_{train}(\theta)$的误差慢慢增大,因为数据越少,模型越容易拟合;$J_{cv}(\theta)$慢慢减少,因为数据越多,模型越精准,所以误差减小。
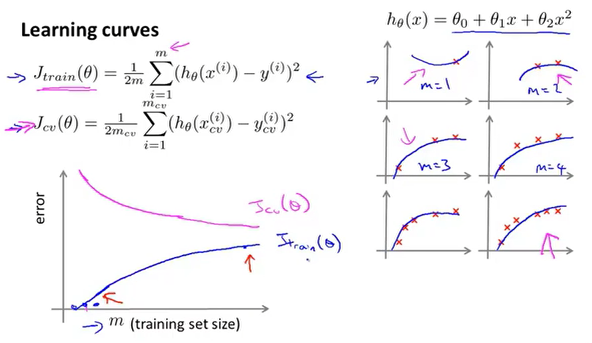
高偏差的模型的学习曲线:
因为参数很少,数据很多,所以随着数据的增多高偏差的模型的$J_{train}(\theta)$和$J_{cv}(\theta)$很接近。这时选择增加数据就不是很好的选择了,可以尝试增加数据的特征。
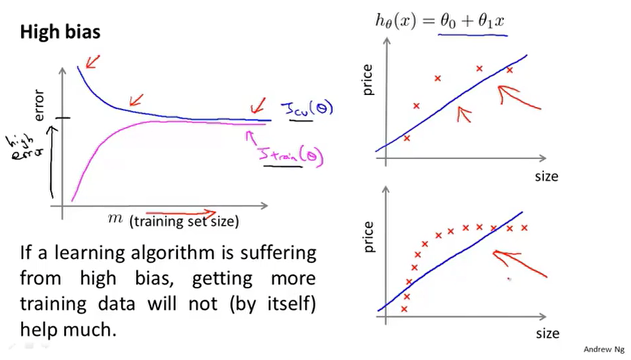
高方差的模型的学习曲线:
高方差的特点是训练误差和验证误差之间有很大的差距,这时可以选择增加数据,随着图像右移可以看出训练误差和验证误差会慢慢接近。
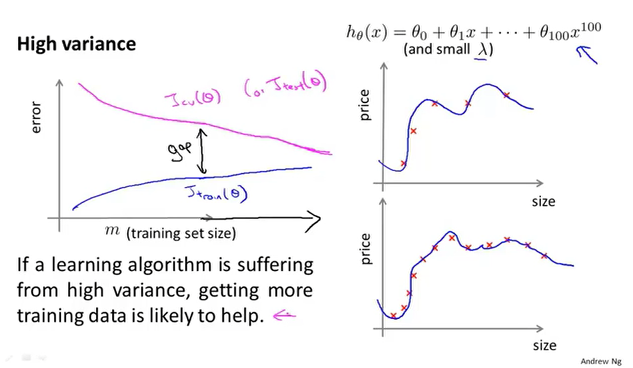
如何抉择

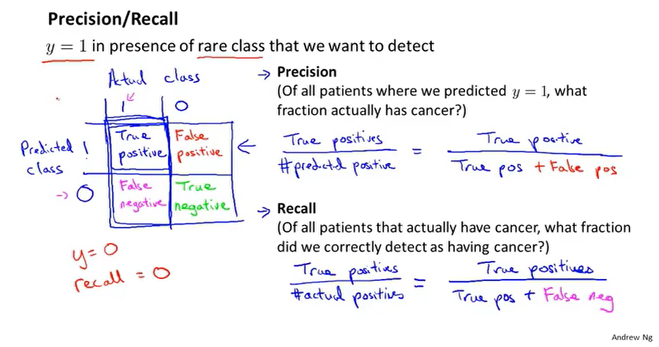
查准率、召回率
例如对癌症的预测,相对于样本数据真实得癌症的人非常少,大概只有0.5%的概率,这样的问题称为偏斜类,一个类中的样本数比另一个类多得多。
对于偏斜类的问题,如何评估模型的精准度呢?可能一个只输出y=1的函数都比你的模型准确。
这里引入了查准率和召回率,对于稀有的样本有:
通常如果阈值设置的比较高,那么对应的查准率高、召回率低;相反如果阈值设置的低,那么查准率低、召回率高。

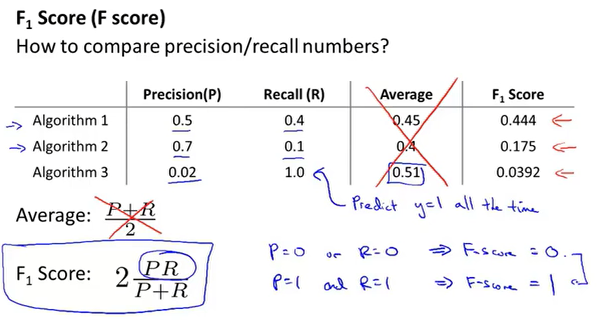
F1 score
如何比较权衡不同的算法呢?
这里使用的$F_1 score$,即调和平均数(倒数的平均数)来衡量。
$F_1 score$会比较照顾数值小的一方,如果PR都为0,$F_1 score=0$;如果PR都为1,$F_1 score=1$
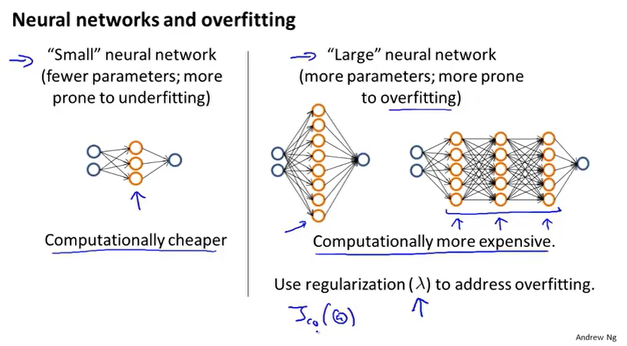
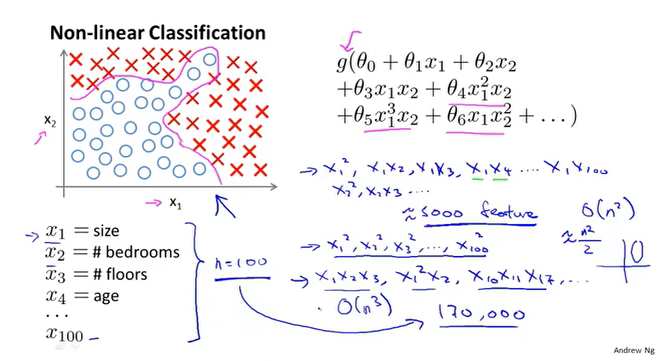
神经网络
大多数的机器学习所涉及到的特征非常多,对于非线性分类问题,往往需要构造多项式来表示数据之间的关系,多项式的组成方式千变万化,这对计算带来一定困扰。
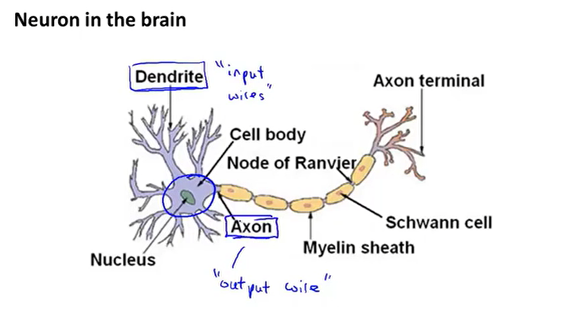
大脑中的神经元结构:
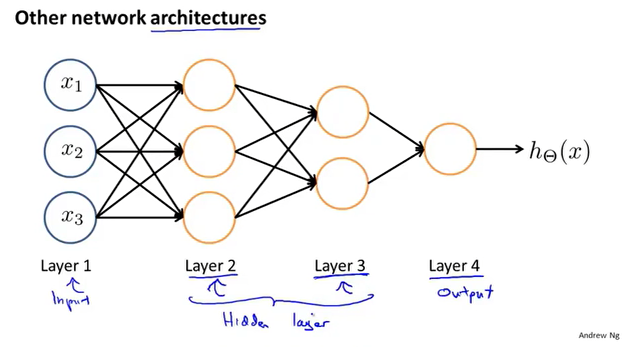
机器学习中的神经网络一般包括三部分,输入层,隐藏层,输出层。
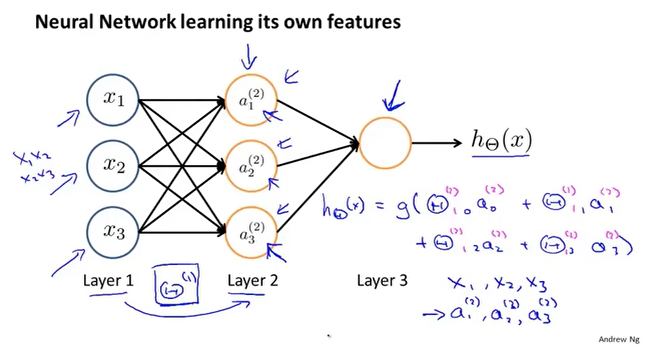
数据从输入层开始,通过激活函数前向传播到第一隐藏层,经过多个隐藏层,最后到达输出层,神经网络表示复杂的逻辑关系,主要是对隐藏层的构造。
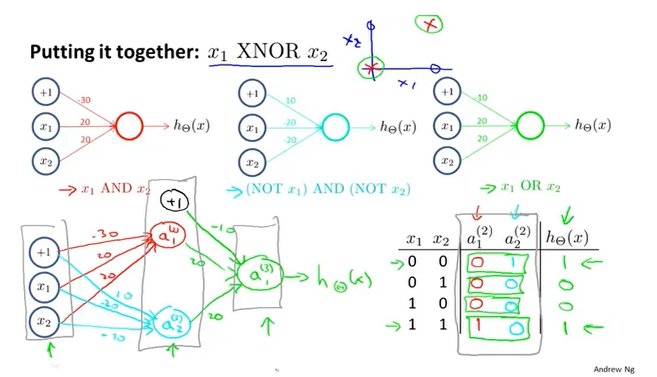
逻辑运算
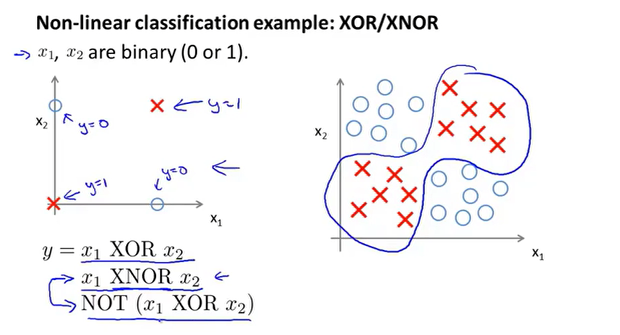
如上为一个XNOR的分类问题,$xnor=(x_1 & x_2) or (\bar{x_1} & \bar{x_2})$,我们可以搭建出每种逻辑运算的神经网络,最终整合得到XNOR的神经网络模型。
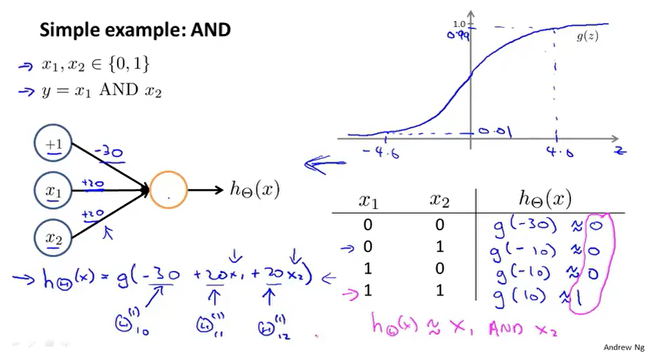
AND运算
OR运算

NOT运算
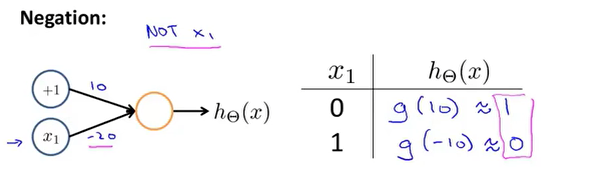
XNOR运算
$xnor=(x_1 & x_2) or (\bar{x_1} & \bar{x_2})$
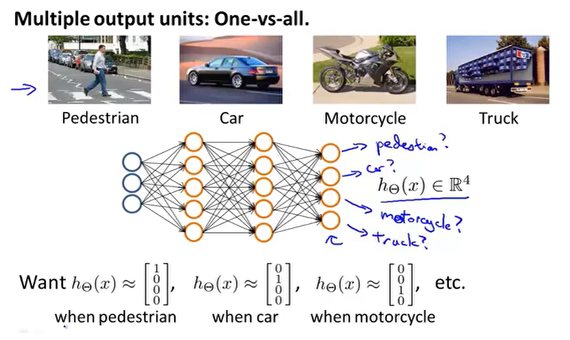
多元分类
通过构建神经网络,每种输出就对应一个分类器。
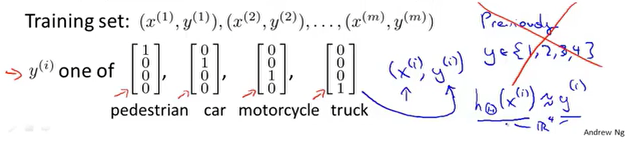
代价函数
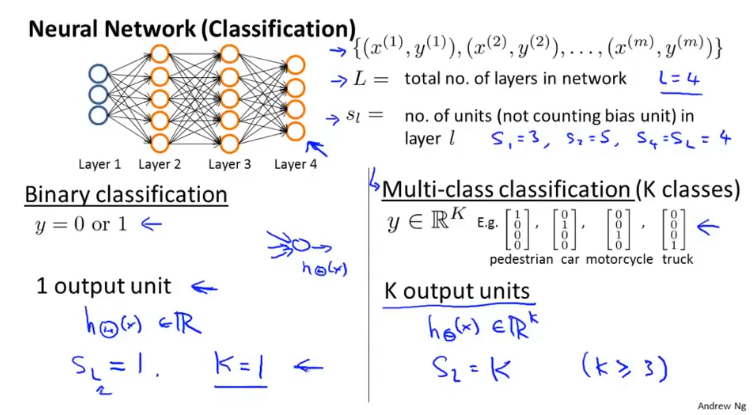
K表示输出层的单元数目,L为神经网络的层数。

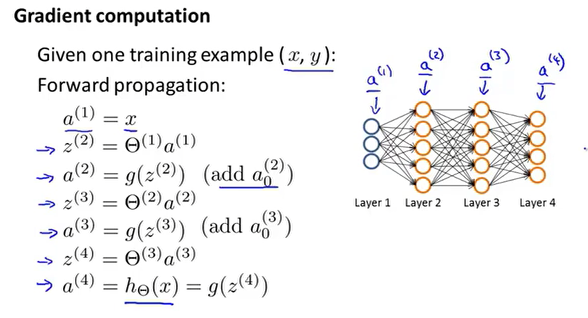
前向传播
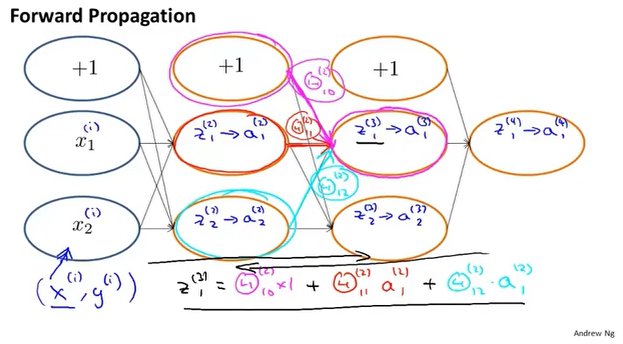
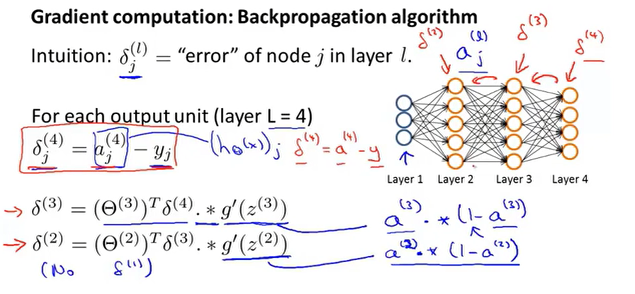
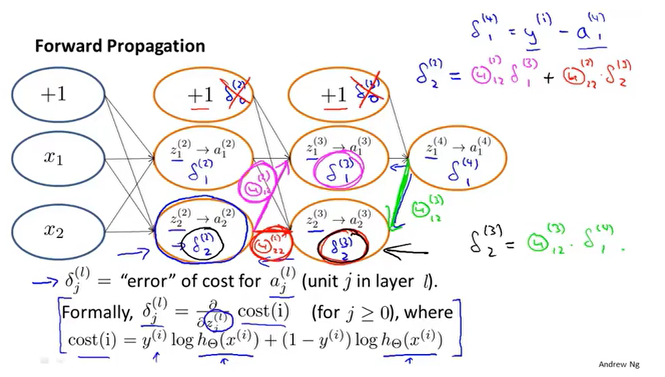
反向传播

随机初始化
在对神经网络进行训练时,theta的取值要随机取值,如果都赋值为0,就会使得每一层的输出值、误差相同,从而存在大量冗余。

梯度检测
在实现反向传播算法时,如何确保梯度计算正确呢?
在数学上可以使用拉格朗日中值定理来近似的表示曲线上某一点的导数,梯度检测正是使用的这种思想。
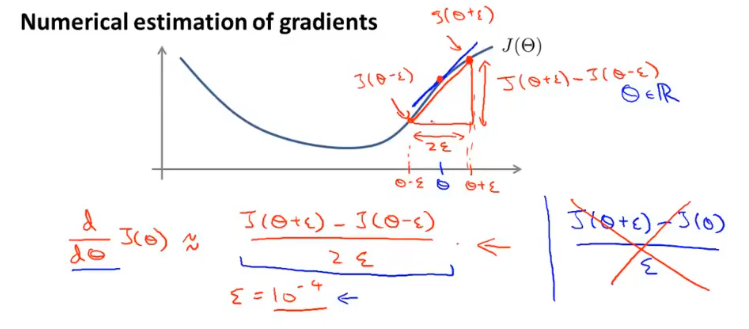
梯度检测的使用,可以对每个参数单独进行验证。


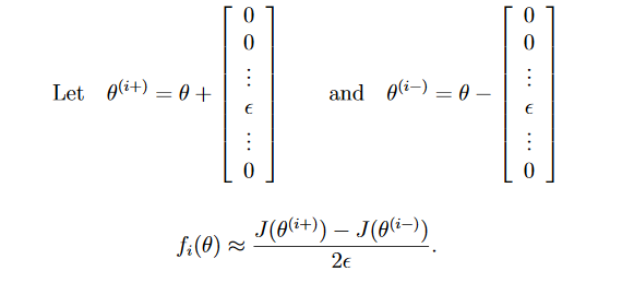
假设通过中值定理得到的梯度为approx_grad,经过反向传播得到的梯度为grad,如果满足以下等式,则说明反向传播得到的梯度精度还行。
梯度计算正确的情况下,当算法进行学习的时候要关闭梯度检测,因为它非常耗时。

支持向量机
逻辑回归模型的图像是一个曲线或复杂的曲线,SVM使用简单函数来近似这个曲线。
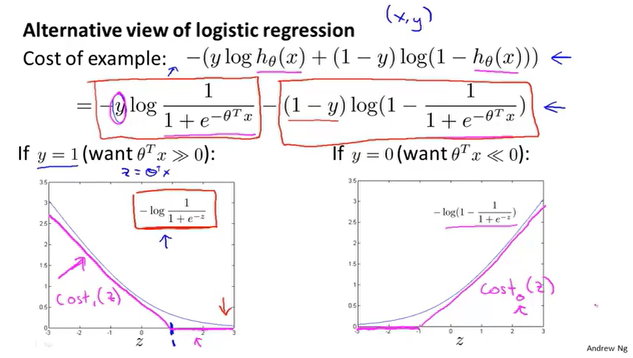
代价函数
支持向量机在逻辑回归的基础上简化了代价函数,逻辑回归使用正则项来权衡$\theta$的大小,以此解决过拟合的问题。SVM也是类似,它是在代价函数上添加系数C,效果等价。
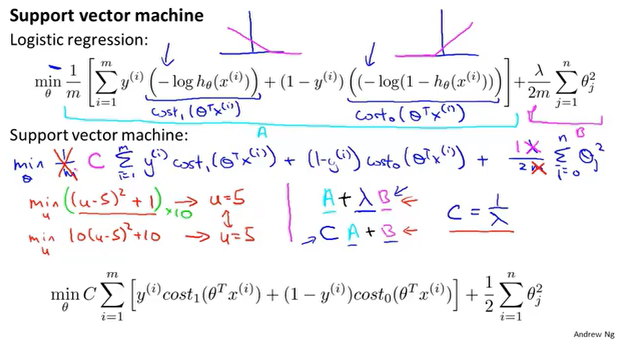
最大边界
SVM又叫做最大边界分类问题,观察代价函数可以得到:

最小化代价函数,就是让左侧代价函数的和尽可能等于0,即对应$\theta^Tx$,另外还有右侧的$\theta^2$的和最小,即向量的模尽可能小。

分类问题的界限有多种可能,SVM对于如下二分类的问题,往往会得到黑色的那条分界线,这条线恰好对应着最大的边界,因此也叫做最大边界分类问题。
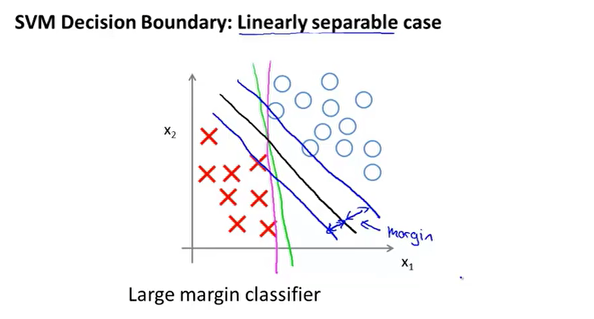
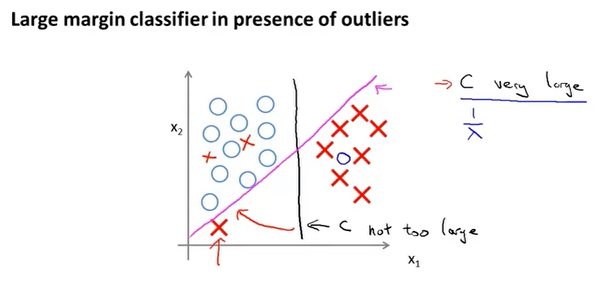
代价函数中的C决定了边界的划分,如果C很大对应逻辑回归的$\lambda$很小,模型过拟合,这样就会的到紫色的分界线,通过C的取值,我们可以决定边界的划分。
证明
向量的内积,等价于投影长度的乘积。
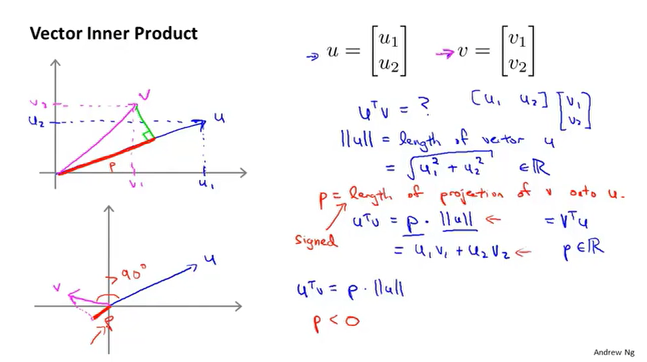
因此$\theta^Tx$可以写为$p||\theta||$。
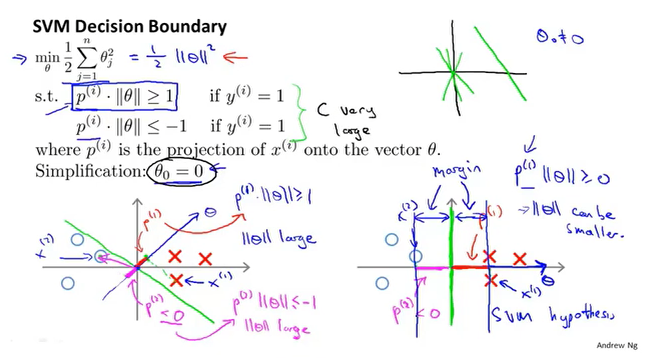
对于左侧的$\theta$,每个x向量在$\theta$上的投影距离很小,要满足条件那么$||\theta||$就要增大,这样最小化代价函数的值就不是最优的,可能发生过拟合,所以SVM会得到类似右侧的边界,这样$||\theta||$尽可能小些,因为投影距离都比左侧的要大,这也是最大边界的原因。
核函数
对于一个非线性决策边界问题,我们可能使用高阶的函数进行拟合,但是是否存在比当前特征刚好的表达形式呢?

我们可以将每种特征表示为$f_i$,使用高斯核函数来做相似度分析。
随机选择三个点作为标记,通过核函数可以得到x对应的新特征。

使用高斯函数的特点:如果相似度很高,即对应的欧几里得距离$\approx 0$对应$f_i=1$,相反如果相似度低对应$f_i\approx 0$。
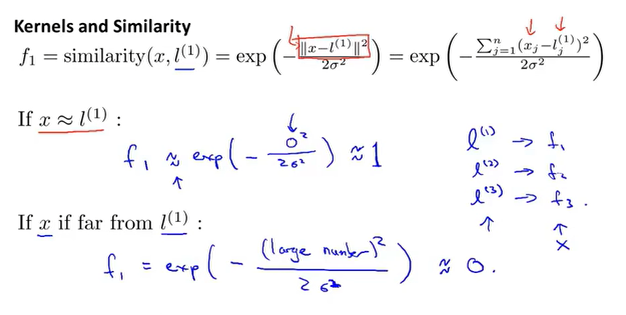
假设我们已经训练好参数$\theta$,那么就可以通过$\theta^Tf \ge 0$来进行预测,即对应红色的决策边界。
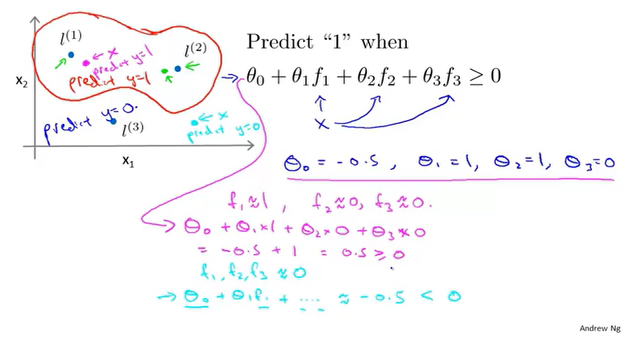
可以直接将训练集中的$x^{(i)}$作为核函数中的$l^{(i)}$。
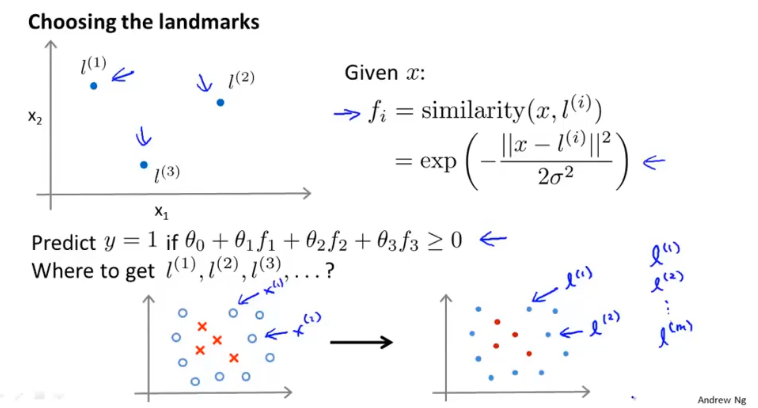
这样对于训练中的数据$x^{(i)}$,都可以得到对应的$f^{(i)}$。

SVM在使用核函数的时候,对应代价函数就可以替换为:

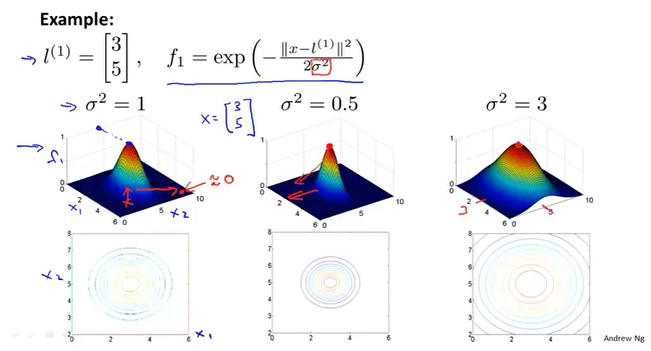
和SVM中的参数C一样,核函数的$\sigma^2$决定了拟合的程度。

k均值
对于没有标签的数据来说,首先根据划分聚类的个数,随机设置聚类中心的位置,然后遍历所有的数据,把每个数据分配到离它最近的坐标,对于同一个簇的数据计算它们坐标的中心位置,并设置为新的聚类中心,以此不断的迭代。
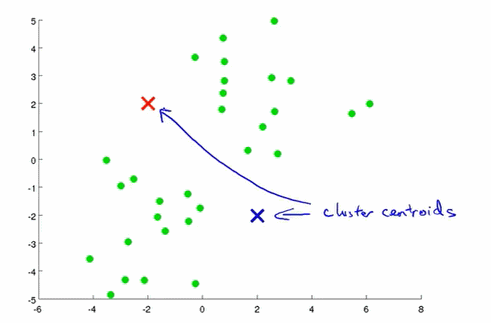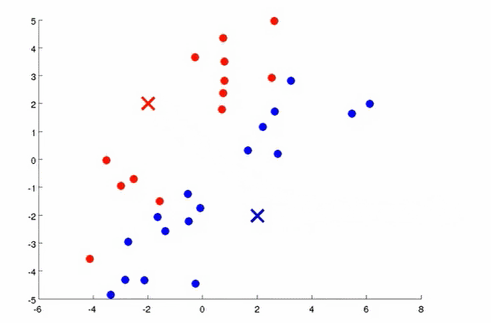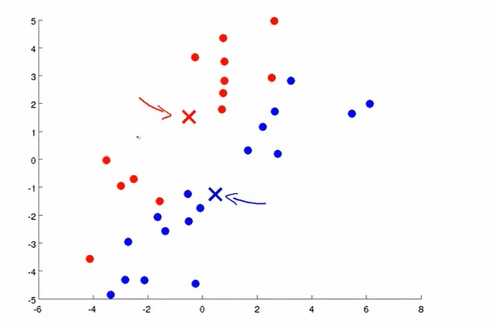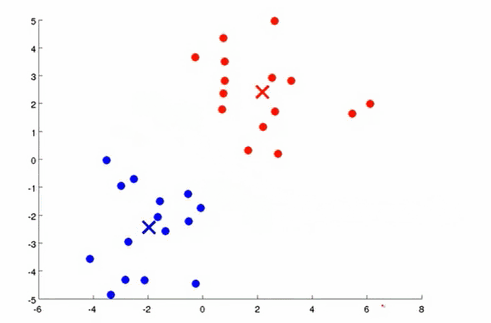

k均值的目标函数是所有点到它所属聚类中心的距离和。

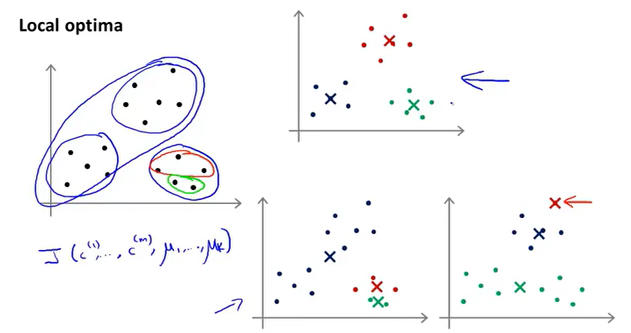
随机初始化,当聚类数量很少时,如果初始化的位置不够好,会得到一个局部最优解,解决方案是多次随机初始化,从而得到一个全局最优解。

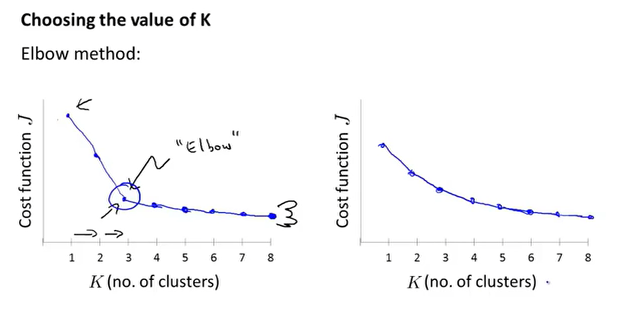
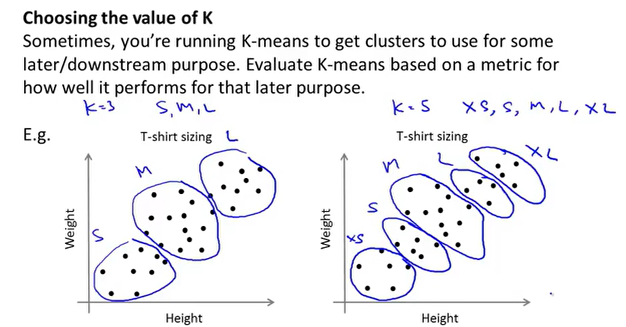
聚类数量的选择,得到聚类数量和代价的图像,根据肘部原则选取(一般不用);或者根据k均值聚类的目的来做判断,比如做衣服尺寸的聚类分析,根据市场需求,3个聚类or5个聚类更适合市场营销等等。
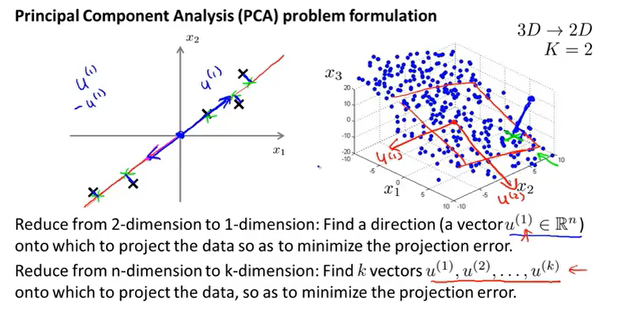
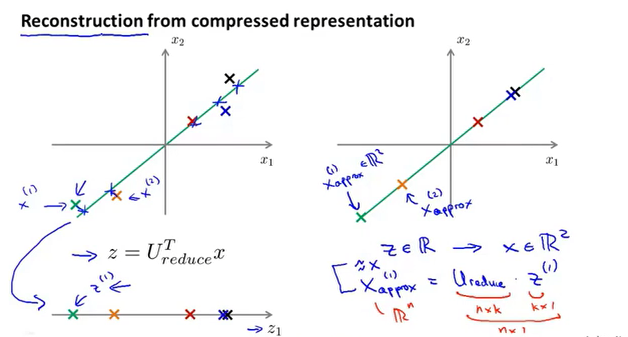
主成分分析(PCA)
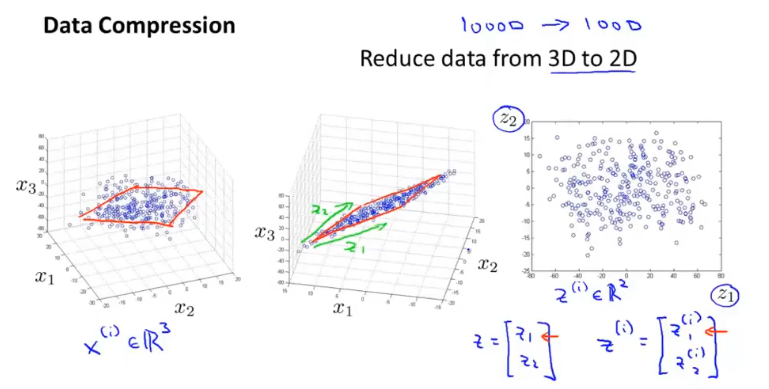
主成分分析(PCA)是一种数据压缩的算法,他将数据压缩到k维度,并使得所有数据投影到新维度的距离最小。
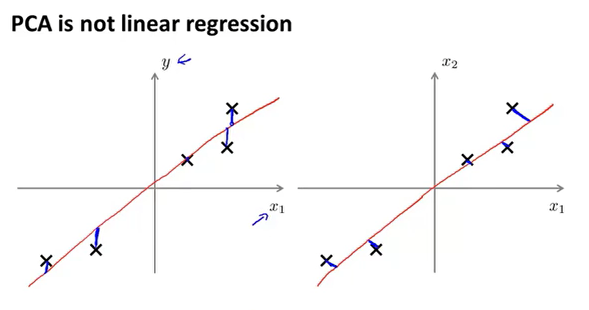
PCA不是线性回归,一个是投影距离,一个是点与直线上点的距离。
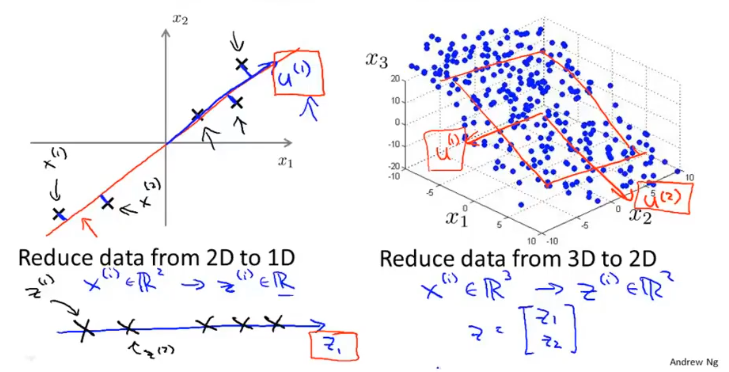
PCA执行过程,首先对数据进行均值归一化,然后计算协方差,最后得到一个k维的矩阵。
首先对数据进行均值归一化,然后确定要压缩的目标维度,即对应向量的个数,PCA的目标是使得所有数据距离新维度的距离最小。


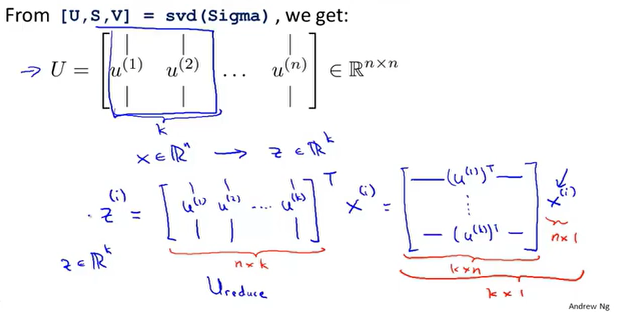
如何确定维度K?


如何得到压缩直线的近似坐标?
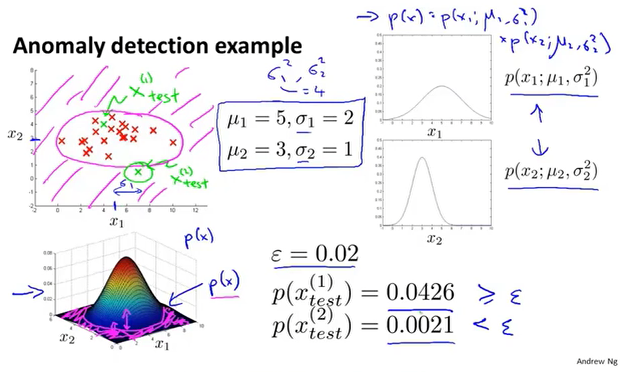
异常检测
高斯分布
可以使用高斯分布来进行异常检测。
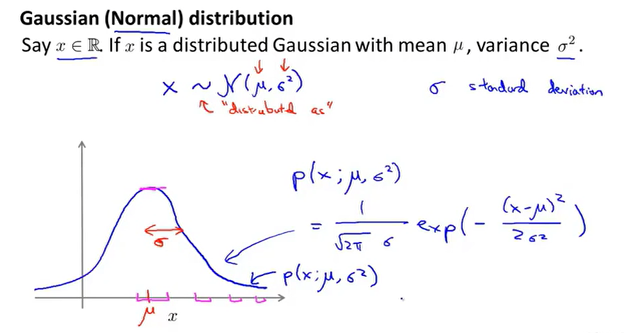
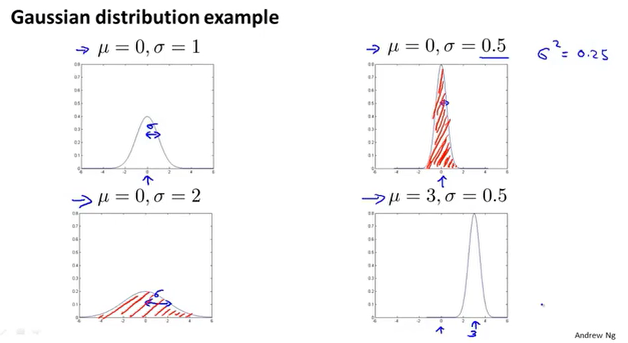
计算m个数据集在每一个维度上的$\mu$和$\sigma^2$,然后根据$p(x)$得到一个概率$\epsilon$,根据概率的大小来定义是否为异常行为。


多变量高斯分布
异常检测算法,往往是把$\mu$附近的数据认为是高频率出现的,表现在图像上类似一个圆形。在一些情况下数据并不是规则分布,单变量的高斯分布不能体现拟合椭圆形状。
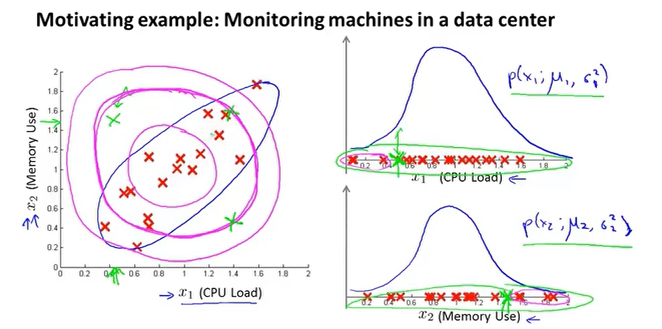
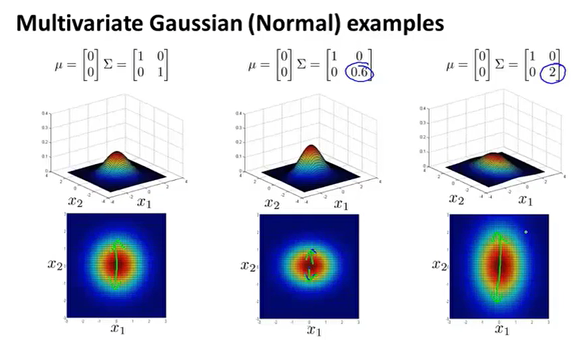
多变量高斯分布引入了协方差矩阵,通过修改矩阵的值来改变高斯分布的情况。
$\Sigma$可以理解为每个特征的缩放比例,这样就可以拟合更多的数据分布。
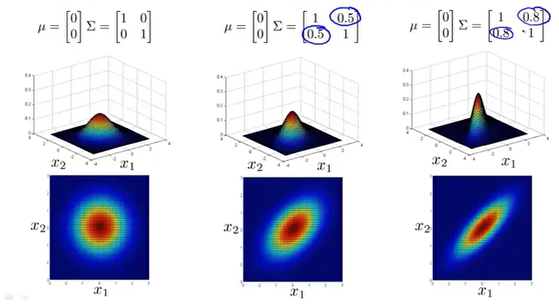
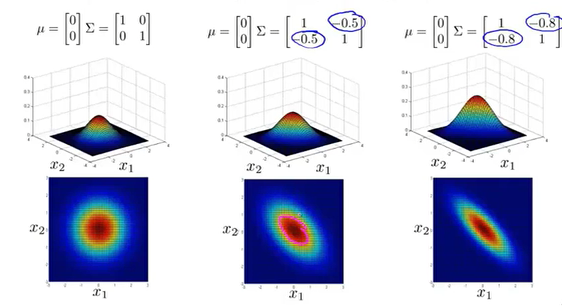
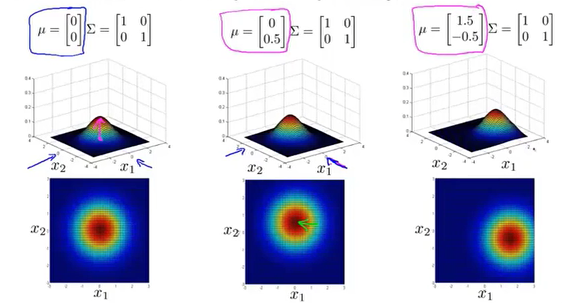

传统的高斯分布实际上是多变量高斯分布的特殊形式,对应矩阵在非对角线上的数为0。
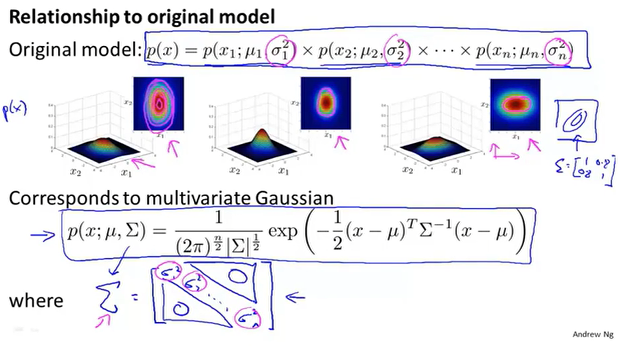
传统的模型需要手动构造异常特征的组合,多变量可以自动的捕捉。不过多变量的计算复杂度高一些。

推荐系统
内容推荐算法
例如一个电影推荐系统,一共有n个用户,m个电影,每部电影都有一定的特征,例如爱情片的比例、动作片的比例。n个用户对看过的电影进行评分,推荐系统做的给用户推荐新电影,预测用户对新电影的评分?
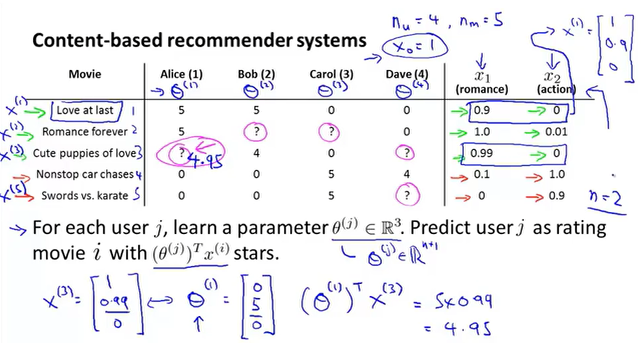
可以使用线性回归的方法进行训练,得到用户对于特征的参数$\theta$,之后就可以根据$\theta^TX$对电影进行打分。

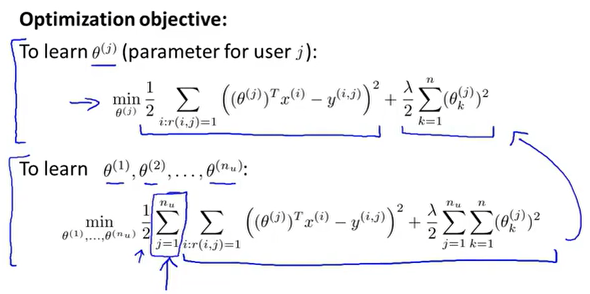
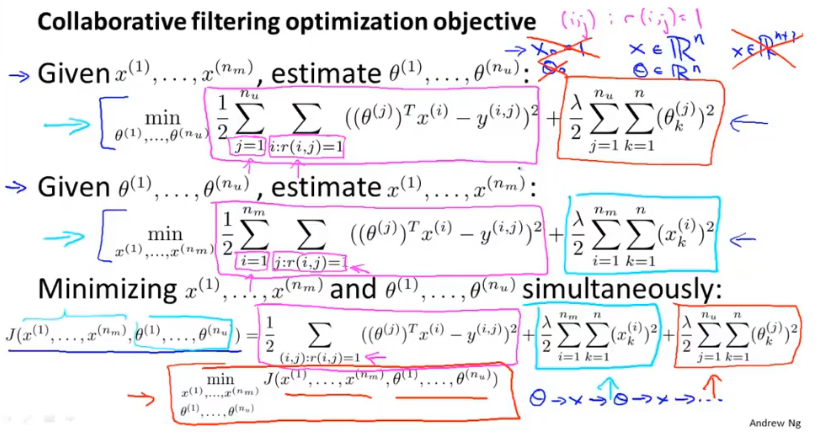
优化目标函数为:

协同过滤
collaborative filtering,用于特征学习,自己学习得到数据的特征值。
我们无法得到每部电影中不同特征的比例,例如电影中爱情和动作的比例?除非人工审核每一部电影,但是太耗时。
这里有一个思路,首先用户根据自己的喜好对特征打分,通过计算可以大致确定已经打过分的电影它的特征值,根据已经确定的特征值,又可以计算出每个用户对这部电影的评分。
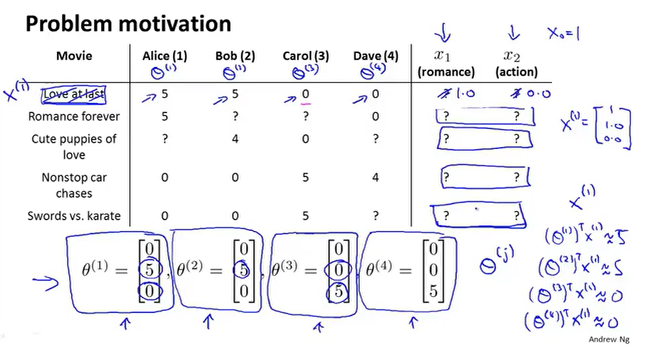
先有鸡还是先有蛋…
根据特征向量$X$可以通过线性回归得到用户的$\theta$向量,通过用户提供的$\theta$向量可以估计每部电影的特征数值。这就有点像鸡和蛋的问题。
我们可以随机选取$\theta$向量计算得到特征数值,然后再通过线性回归去更新$\theta$,这样不停的迭代直到最后的收敛。

我们也可以将两种函数合并为一个目标函数:

低秩矩阵分解
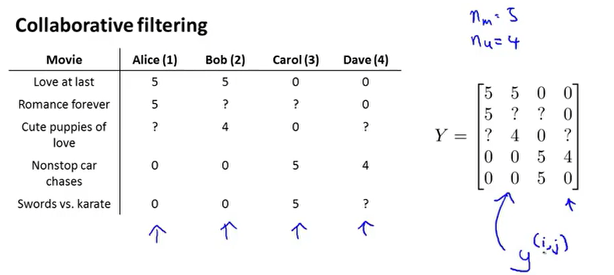
可以把n个用户对m部电影的评分结果表示为$m\times n$的矩阵。
这个矩阵可以表示为$X\theta^T$。
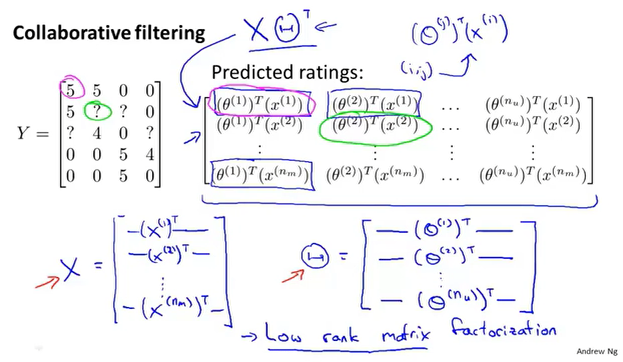
通过特征值之间的偏差,我们可以找到类型相近的电影。

均值规范化
之前无论是参数$\theta$还是特征$X$,都基于每个用户都对多个电影进行的评分,每部电影也被多个用户评分。对于新用户,他可能还没有对任何一部电影进行评分,一种思路就是把所有用户对每部电影的评分的均值作为新用户的初始评分。
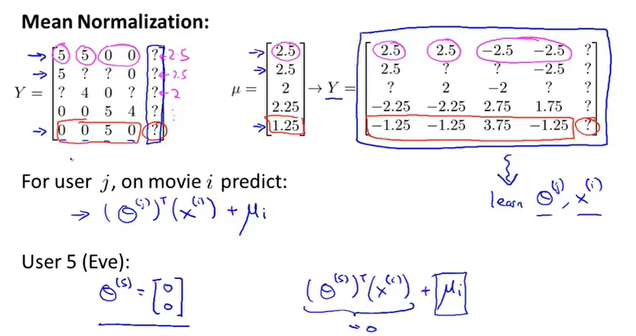
随机梯度下降
Stochastic gradient descent
随机梯度下降算法对每个数据分开处理,对一个数据更新所有的参数。
梯度下降算法是在每次更新参数的时候,需要计算所有数据。
对比下来SGD的速度要快一些,不过收敛性可能没GD好。

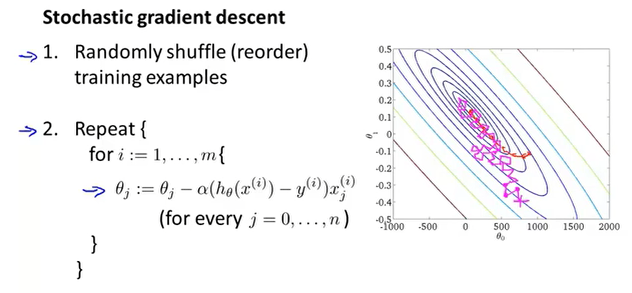
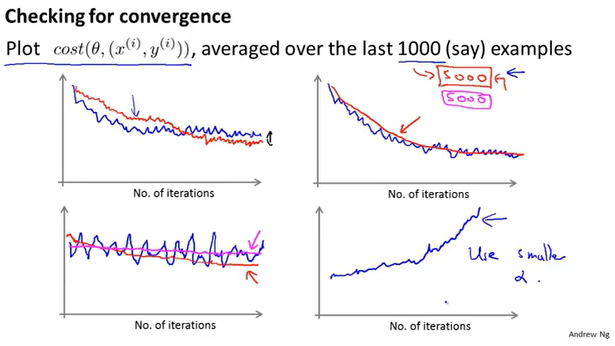
如何判断SGD的收敛?
首先定义cost函数,然后每隔1000次迭代画出cost的图像,根据均值来判断。
如果噪声太多图像上下震荡,可以选择更多的迭代次数。
如果随着迭代次数cost增加,那么选择更小的$\alpha$。

SGD一般不能得到全局最优,他会一直在最优值附近徘徊。
学习率的大小一般保持不变,一个思路是可以动态的改变学习率$\alpha$的大小来提高准确度,比如随着迭代次数的增加慢慢减小$\alpha$的值。
Mini-Batch
Mini-Batch gradient descent
将数据分为多份,对每一份执行GD,相当于GD和SGD的综合。
b可以取[10,100]。

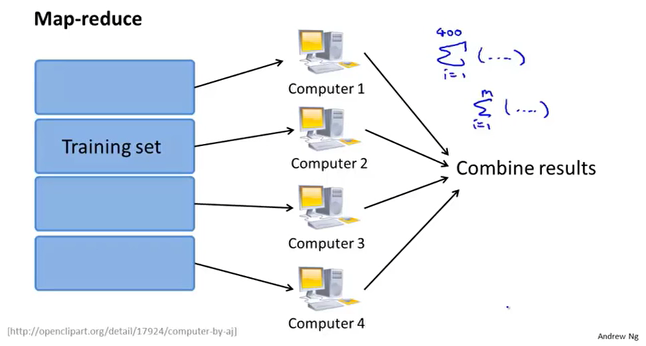
Map-reduce
Map-reduce and data parallelism。
Map-reduce利用了线性回归求和运算的特性,将GD对整个数据的求和处理,分摊到多个服务器上执行,最后各个服务器把结果汇总到一起进行合并。
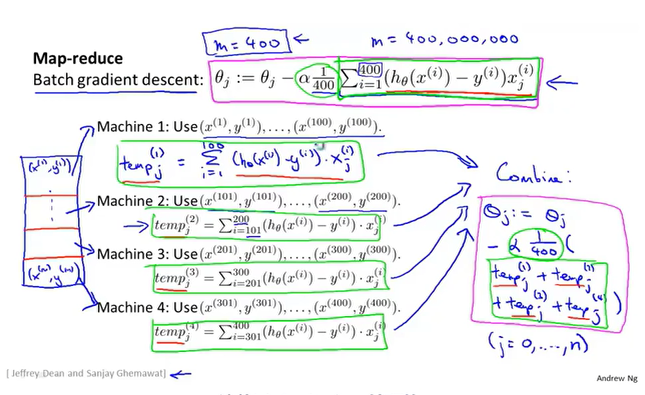
逻辑回归也可以这样搞。

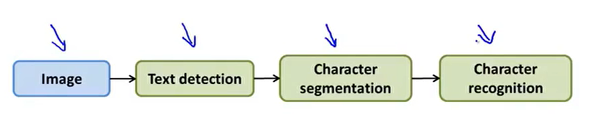
OCR
pipeline

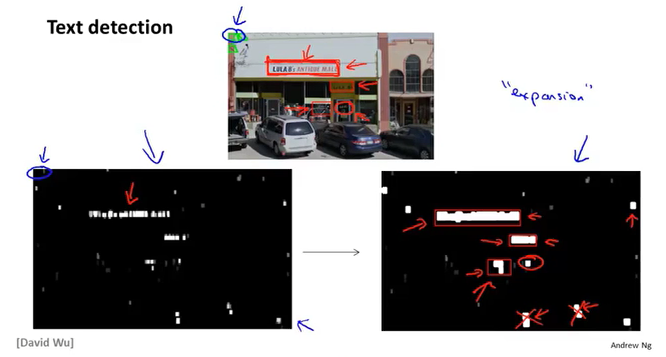

滑动窗口

获取数据
下载字体,然后将它们放到一个随机北京图片上。

对图像进行人工扭曲
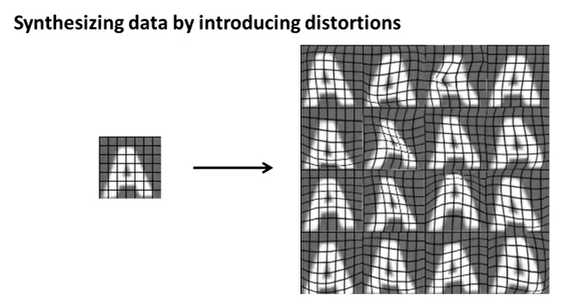
对语音文本加入不同的背景干扰。

首先确保算法已经有很低的偏差,整体的模型ok,然后在考虑加数据,否则只是徒劳。
然后考虑加数据的人工和时间成本。

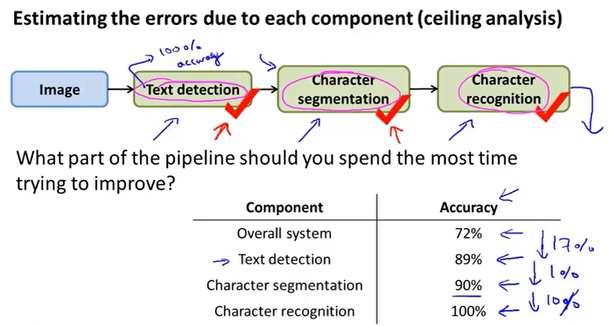
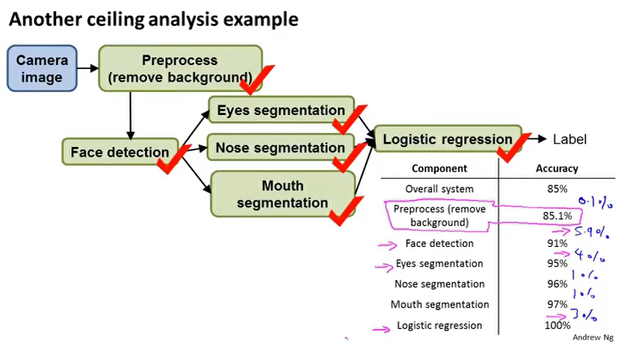
上限分析
对多个模块进行分析,让其中一个模块达到100%的准确率,然后判断它能提高整个系统多少准确率。
课后作业
]]>参考项目:github.com/ttroy50/cmake-examples
中文学习地址:cmake-examples-Chinese
basic
hello cmake
1 | . |
1 | # CMakeLists.txt |
1 | message("CMAKE_SOURCE_DIR: ${CMAKE_SOURCE_DIR}") |
| Variable | Info |
|---|---|
| CMAKE_SOURCE_DIR | CMakeLists.txt的根目录 |
| CMAKE_CURRENT_SOURCE_DIR | 当前处理CMakeLists.txt的目录 |
| PROJECT_SOURCE_DIR | 项目根目录 |
| CMAKE_BINARY_DIR | 执行cmake的目录(build) |
| CMAKE_CURRENT_BINARY_DIR | 当前所在的build目录 |
| PROJECT_BINARY_DIR | 项目构建的目录 |
hello headers
1 | . |
1 | # CMakeLists.txt |
static library
1 | $ tree |
1 | # CMakeLists.txt |
1 | # 创建静态库文件 libhello_library.a |
shared library
1 | $ tree |
1 | # CMakeLists.txt |
1 | # 创建动态库文件 libhello_library.so |
installing
1 | $ tree |
1 | # CMakeLists.txt |
1 | # 指定make instal的目录为./install |
build type
1 | $ tree |
1 | # CMakeLists.txt |
Cmake提供四种构建类型:
- Release,
-O3 -DNDEBUG - Debug,
-g - MinSizeRel,
-Os -DNDEBUG - RelWithDebInfo,
-O2 -g -DNDEBUG
1 | # 用户在cmake时指定编译类型 |
compile flags
1 | $ tree |
1 | // main.cpp |
1 | # CMakeLists.txt |
1 | # 为特定的可执行文件或库设置compile flags |
third party library
1 | # 安装依赖 |
1 | $ tree |
1 | // main.cpp |
1 | # CMakeLists.txt |
查找库
1 | # find package |
Boost为库的名称
1.46.1是最低的版本号
REQUIRED表示这是必需的库,如果找不到报错。
COMPONENTS是要查找的库列表
检查库是否存在
大多数被包含的库都会设置变量xxx_FOUND
1 | # check if boost was found |
如果库存在,一般会设置如下参数用来定位库:
xxx_INCLUDE_DIRS- 头文件位置xxx_LIBRARY- 库位置
1 | # Include the boost headers |
别名
大多数modern CMake库包含别名,例如对于boost来说可以使用:
Boost::boostfor header only librariesBoost::systemfor the boost system library.Boost::filesystemfor filesystem library.
1 | target_link_libraries( third_party_include |
compiling with clang
1 | # install clang |
1 | $ tree |
1 | # CMakeLists.txt |
1 |
|
CMake的编译器选项:
- CMAKE_C_COMPILER - The program used to compile c code.
- CMAKE_CXX_COMPILER - The program used to compile c++ code.
- CMAKE_LINKER - The program used to link your binary.
building with ninja
1 | $ tree |
CMake包含多种生成器:cmake --help
1 | Generators |
接下来使用Ninja进行构建:
1 | # install ninja-build |
cpp standard
设置c++的编译标准。
1 | $ tree |
1 | // main.cpp |
1 | # CMakeLists.txt |
另外还有两种设置c++ standard的方法:
1 | ####################################################################### |
sub projects
- sublibrary1 - A static library
- sublibrary2 - A header only library
- subbinary - An executable
1 | $ tree |
1 | # CMakeLists.txt |
1 | # sublibrary1/CMakeLists.txt |
1 | # sublibrary2/CMakeLists.txt |
1 | # subbinary/CMakeLists.txt |
code generation
configure files
- CMakeLists.txt - Contains the CMake commands you wish to run
- main.cpp - The source file with main
- path.h.in - File to contain a path to the build directory
- ver.h.in - File to contain the version of the project
1 | $ tree |
1 | // main.cpp |
通过CMake的configure_file()自动生成代码。
1 | # CMakeLists.txt |
protobuf
protobuf是google开源的对字符串进行序列化的库,将要序列化的数据定义写在原始文件.proto配置文件中,protobuf将数据序列化为二进制格式,节省内存,加快了数据的传输,但是降低了可读性。
- AddressBook.proto - proto file from main protocol buffer example
- CMakeLists.txt - Contains the CMake commands you wish to run
- main.cpp - The source file from the protobuf example.
1 | $ tree |
1 | # CMakeLists.txt |
Ollama
1 | curl -fsSL https://ollama.com/install.sh | sh |
我是在服务器上安装的,为了支持远程访问,需要修改下配置文件。
1 | sudo vim /etc/systemd/system/ollama.service |
ollama所有可用模型:https://ollama.com/library
1 | # 重启服务 |
同时部署多个模型 [可选]
1 | # 默认端口为11434, 这里额外部署一个11435的服务 |
Continue
在vscode的插件库上安装Continue插件。
在
config.json中添加模型配置文件。如果使用本地模型,可以注释掉
"apiBase": "http://your_server_ip:11435",如果使用的是默认的ollama服务,端口11435改为11434。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56"models": [
{
"title": "Codellama 7b",
"provider": "ollama",
"model": "codellama:7b",
"apiBase": "http://your_server_ip:11435"
},
{
"title": "Codellama 13b",
"provider": "ollama",
"model": "codellama:13b",
"apiBase": "http://your_server_ip:11435"
},
{
"title": "Codellama 34b",
"provider": "ollama",
"model": "codellama:34b",
"apiBase": "http://your_server_ip:11435"
},
{
"title": "StarCoder2 3b",
"provider": "ollama",
"model": "starcoder2:3b",
"apiBase": "http://node1:11435"
},
{
"title": "StarCoder2 7b",
"provider": "ollama",
"model": "starcoder2:7b",
"apiBase": "http://node1:11435"
},
{
"title": "starcoder2:15b",
"provider": "ollama",
"model": "starcoder2:15b",
"apiBase": "http://node1:11435"
},
{
"title": "Llama2 7b",
"provider": "ollama",
"model": "llama2:7b",
"apiBase": "http://your_server_ip:11435"
},
{
"title": "Llama2 13b",
"provider": "ollama",
"model": "llama2:13b",
"apiBase": "http://your_server_ip:11435"
},
{
"title": "Llama2 70b",
"provider": "ollama",
"model": "llama2:70b",
"apiBase": "http://your_server_ip:11435"
}
],
效果
Ctrl + L选中代码,弹出聊天窗口,可以直接询问LLM,例如编写单元测试,检查bug。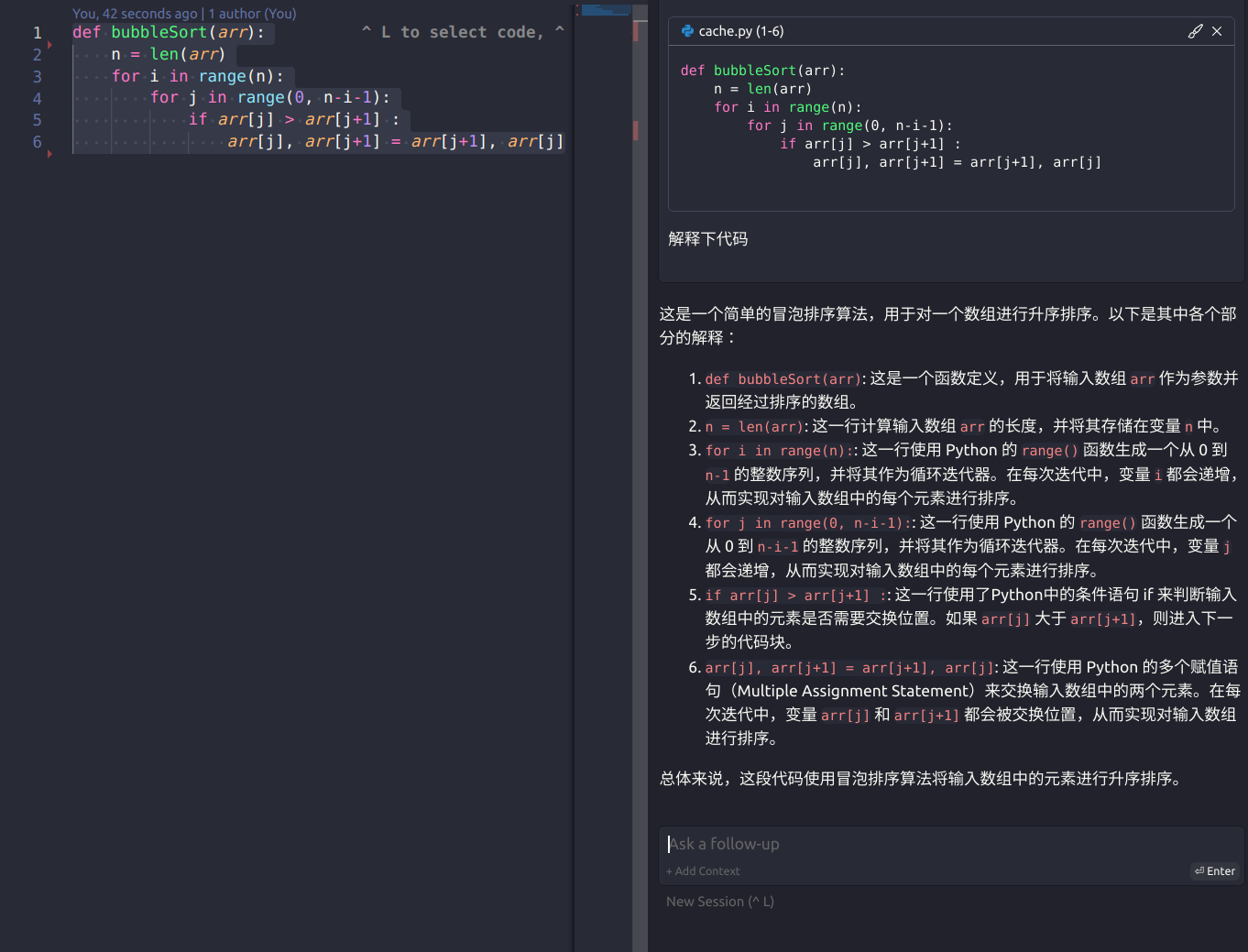
Ctrl + I插入代码,弹出prompt输入框,根据需求生成代码。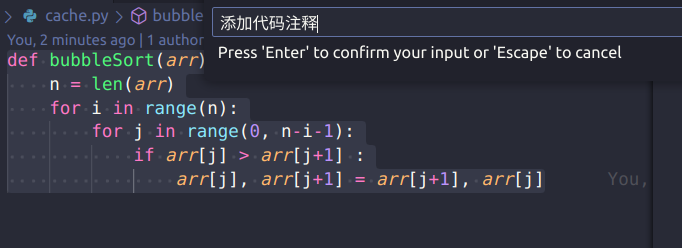
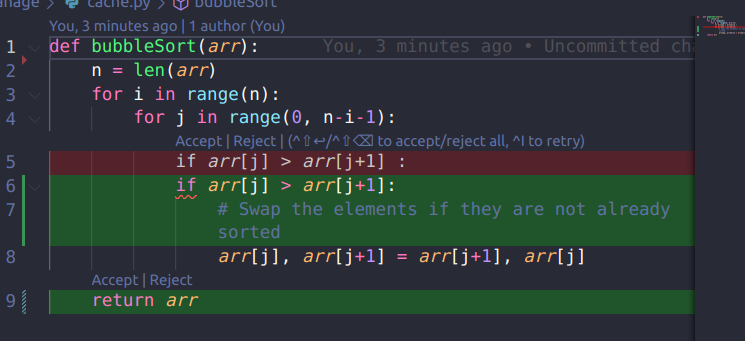
Commit格式
1 | feat: 新增 feature |
常用命令
1 | 查看hash对应的文件内容 |
工作流
1 | # 创建本地分支 |
环境配置
配置用户信息
1
2git config --global user.name "Sanzo00"
git config --global user.email "arrangeman@163.com"生成ssh-key
1
ssh-keygen -t rsa -C "arrangeman@163.com"
将生成的公钥文件
~/.ssh/id_rsa.pub添加到Github上。
版本回退
修改文件后提交修改到版本库
1
2git add .
git commit -m "xxx"查看历史版本
1
2git log # 显示最近到最远的提交
git reflog # 显示所有执行过的命令回退到历史版本
1
2
3
4
5
6
7
8
9
10
11# 回到上一个版本
git reset --hard HEAD^
# 回到上上一个版本
git reset --hard HEAD^^
# 回到上一个版本 (同上)
git reset --hard HEAD~1
# 回到制定版本
git reset --hard commit_id
工作区和暂存区
工作区: 存放项目的目录
暂存区
1
2
3
4# 将文件的修改添加到暂存区中
git add "file"
# 把暂存区的修改提交到分支
git commit
撤销修改
1 | # 本地修改没有git add到暂存区, 回退到上一个git add或git commit |
删除文件
准备工作
1
2
3
4
5
6
7
8
9
10
11# 在工作区新建test文件
touch test
# 添加到暂存区
git add test
# 提交到分支
git commit -m "add test"
# 在本地删除test
rm test
# 工作区和版本库不一致
git status确定删除文件test
1
2
3git rm test
# git add test 等价
git commit -m "remove test"恢复工作区文件(误删)
1
git checkout -- <file>
只删除记录中的文件,本地不删除
1
git rm --cached <file>
远程仓库
添加远程库
1
2
3
4
5
6
7
8
9# 初始化本地目录为git仓库
git init
# 关联一个远程库
git remote add origin git@github.com:your_name/repo_name.git
git push --set-upstream origin master
# 本地同步远程仓库
git pull origin master
# 提交到远程仓库
git push origin master修改远程目录
1
git remote set-url origin git@github.com:your_name/repo_name.git
克隆远程库
1
git clone git@github.com:your_name/repo_name.git
本地仓库
本地仓库可以用于本地端的同步,例如将本地文件定时同步到硬盘这样的场景。
比如本地的文件夹为files。
1 | 将文件夹初始化为git目录。 |
创建与合并分支
创建新分支
1
2
3
4
5
6
7
8# 创建dev分支
git branch dev
# 切换分支
git checkout dev
# 查看当前分支
git branch
# 查看所有分支
git branch -a合并分支
1
2
3
4
5
6# 切换到主分支, 切换前要git commit
git checkout master
# 合并dev到当前分支
git merge dev
# 删除dev分支
git branch -d dev
解决冲突
当master和dev同时修改文件, 在git merge时会出现冲突, 需要手动解决冲突, 重新提交.
1 | # 查看冲突信息 |
分支管理
1 |
|
Bug分支
当dev分支的工作未完成, 你需要紧急修复buf, 这时可以把当前分支暂时储存起来. 完成其他工作之后, 可以恢复现场继续工作.
1 | # 储存现场 |
在上面bug分支修复的错误, 在当前dev上同样也存在问题, 可以使用cherry-pick复制一个commit, 同事git会新创建一个commit
1 | git cherry-pick commit_id |
更简单的, 可以先用git stash报工作现场储存起来, 然后在当前分支修复bug 之后恢复现场继续工作.
Feature分支
当需要添加新功能时, 可以创建feature分支, 测试完成之后, 再合并到当前分支.
1 | # 创建feature分支 |
多人协作
1 | # 查看远程仓库 |
Rebase
多次本地提交或从远端pull下来之后, 本地的版本库会同时有多个commit, 通过–graph查看会觉得混乱, 可以使用rebase, 将多个commit合并成一个, 使得分支变得顺滑~.
1 | # 合并commit |
.gitignore
1 | # 忽略特殊文件 |
git服务器
安装git
1 | sudo apt install git |
新建git用户
1 | sudo adduser git |
公钥登录
将设备的id_rsa.pub文件导入到服务器的home/git/.ssh/authorized_keys中。
如果本地的用户名和服务器的用户名不一致,需要配置/home/user/.ssh/config文件
1 | Host server # 别名 |
初始化
选定服务器的/srv/git/
1 | # 新建目录作为git的工作目录 |
禁用shell登录
编辑/etc/passwd
1 | git:x:1002:1002:,,,:/home/git:/bin/bash |
改为:
1 | git:x:1002:1002:,,,:/home/git:/usr/bin/git-shell |
新建仓库
1 | sudo git init --bare /srv/git/sample.git |
也可以将本地的git项目上传到服务器:
1 | # 首先将本地的项目导出为.git目录 |
克隆项目
1 | git clone git@server:/srv/git/sample.git |
空分支
1 | # 创建空分支 empty |
V2ray
服务端
测试ip:ping.chinaz.com
证书申请:https://freessl.cn/
1 | #X-ui面板安装 |
客户端
Android,linux,macOS 安装包:https://github.com/v2fly/v2ray-core/releases
v2ray客户端配置文件:https://github.com/Sanzo00/files/blob/master/other/v2ray.json
linux端下载v2ray安装包之后,可以选择安装到本地或者直接运行可执行文件。
安装到本地
1 | wget https://raw.githubusercontent.com/v2fly/fhs-install-v2ray/master/install-release.sh |
直接运行可执行文件
1 | nohup ./v2ray run config.json > v2ray.log 2>&1 & |
Clash
开源桌面应用
Mac:ClashX
Windows:ClashForWindows
Android:ClashForAndroid
服务器配置
下载对应系统的可执行文件:Dreamacro/clash release
V2ray to Clash节点转换工具:v2rayse.com/node-convert
1 | cd ~/software |
创建systemd配置文件
1 | sudo vim /etc/systemd/system/clash.service |
1 | [Unit] |
/home/sanzo/software/clash/clash is you clash executable file
/home/sanzo/software/clash/ is your clash config directory
使用systemctl控制clash的运行:
1 | sudo systemctl emable clash |
网络测试
1 | wget google.com |
设置终端代理
终端代理
1 | vim ~/.bashrc |
git代理
对http和https代理
1 | # http and https |
对ssh代理:
1 | sudo apt install connect-proxy |
用户管理
1 | # 创建用户sanzo,指定home目录和登陆的shell |
进程管理
后台执行
1 | # 查看后台任务 |
查找/终止进程
1 | # 查看占用端口的PID |
终止指定名称的进程:kill.sh
1 | # check input args |
常用命令
wc
1 | # 查看文件的行数 |
date
1 | # 日期 |
cal
1 | # 显示本月的日历 |
ssh
1 | # 将远端服务器10.1.1.1的8888端口映射到本地的8888端口 |
head/tail
1 | # 前1000行 |
grep
1 | # 查找当前目录下所有包含'void main()'的文件 |
gzip
1 | # 解压到DIR目录 |
tar
1 | # 解压到DIR目录 |
Miniconda
Miniconda是一个轻量级的Conda包管理器
安装包
所有安装包:repo.anaconda.com/miniconda
Linux: python3.8 Miniconda3 Linux 64-bit
python3.7 Miniconda3 Linux 32-bit
1 | # 以前的版本没有ssh问题 |
配置
初始化终端:
1 | ~/miniconda3/bin/conda init |
如果失败可以手动添加bin目录。
1 | echo "export PATH=\$PATH:/home/pi/miniconda3/bin" >> .bashrc |
使用
新建环境
1 | # 新建名称为test的环境 |
查看所有的环境
1 | conda env list |
使用环境
1 | # 激活环境 |
rpi
armv7l: miniconda3-latest-linux-armv7l.sh
Berryconda3-2.0.0-Linux-armv7l.sh
arm版本的miniconda最高只能安装python3.4,如果需要安装更高版本的python,需要第三方conda,这里使用的是 berryconda,目前最高支持到python3.6。
1 | conda config --add channels rpi |
venv
python自带的虚拟环境模块
1 | # 新建 |
https://www.python.org/ftp/python/3.8.5/Python-3.8.5.tgz
Pytorch
old version lib torch: https://github.com/pytorch/pytorch/issues/40961
Pytorch,选择对应cuda版本。
1 | torch.version # PyTorch version |
build
1 | # install pytorch and dependences |
test
1 | # CMakeLists.txt |
1 |
|
references
old version lib torch: https://github.com/pytorch/pytorch/issues/40961
https://dev-discuss.pytorch.org/t/universal-binaries-for-libtorch-mac/229
https://github.com/pytorch/pytorch/issues/63558
jupyter notebook
ipykernel
通过ipykernel管理jupyter notebook的内核。
1 | # 激活环境 |
远程访问
生成密钥
1 | # 通过ipython生成密码 |
然后就可以通过https://ip:8888远程访问jupyter notebook
- RAG的背景:介绍下LLM的背景知识。存在那些问题?
- RAG是什么?RAG如何解决LLM的问题的?
- RAG的研究现状?RAG还存在那些问题?
背景
什么是LLM?
大语言模型(Large Language Model,LLM)是基于海量数据集进行预训练的超大规模的深度学习模型。OpenAI发布的ChatGPT使人们意识到,具有足够的训练数据和巨大的参数的神经网络模型可以捕获人类语言的大部分语法和语义。此外LLM具有一定的常识,通过训练可以基础大量的事实。LLM具有很多的实际应用,例如文案写作,知识问答,文本分类,代码生成,文本生成等。虽然LLM在很多领域具有出色的表现,但是它面临诸如幻觉,过时的知识,缺乏可解释性等挑战。
什么是RAG?
检索增强生成(Retrieval Augmented Generation,RAG),RAG通过外挂知识库的方式可以有效缓解LLM的问题。
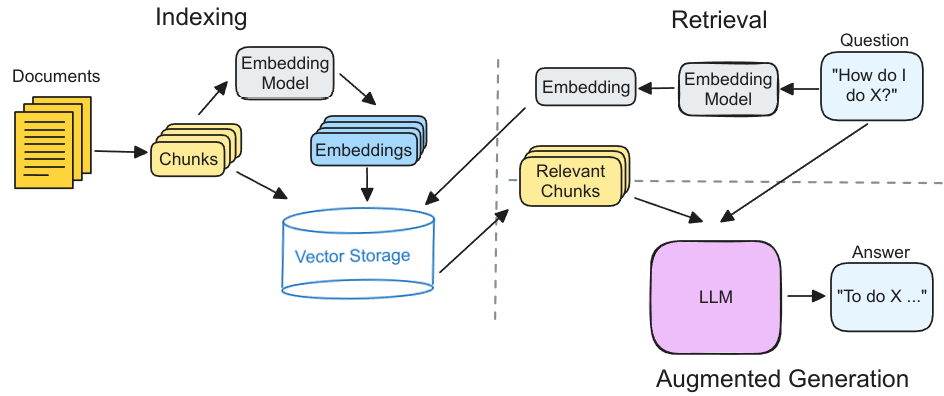
图1是RAG的执行流程,分为索引,检索和增强生成三个部分。
- 索引:对外部知识库进行向量索引,用于后续检索。首先,将文档划分为多个文本块(chunk)。每个文本块通过嵌入模型得到对应的向量表示,然后存储这些文本块和向量到向量数据库中。
- 检索:首先,用户输入的问题经过相同的嵌入模型得到向量表示。然后,向量数据库查找K个相似的向量并返回对应的文本块。
- 增强生成:检索得到的文本块和用户的问题一起发送到大模型,以生成最终的答案。
研究现状
Graph RAG
在介绍Graph RAG之前,先总结下传统向量RAG存在的问题:
- 由于信息分散导致的检索不完整性。
- 由于语义导致的不准确性。
举个具体的例子,例如我们基于《乔布斯自传》来回答用户的问题。与用户问题相关的文本块可能有30个,而且它们分散的存储在书中的不同位置。此时,如果只取top K个片段很难得到这种分散,细粒度的完整信息。而且这种方法容易一楼相互关联的文本块,从而导致检索信息的不完整。
另外,基于嵌入的语义搜索存在不准确的问题,例如“保温杯”和“保温大棚”,这两个关键词在语义空间上存在很大的相似性,然而在真实的场景中,我们并不希望这种通用语义下的相关性出现,进而作为错误的上下文而引入”幻觉“。
Graph RAG是一种使用知识图谱(Knowledge Graph,KG)来组织外部数据的RAG。与向量RAG相比,Graph RAG具有更加细粒度的知识形式,而且,通过在图上查询目标实体的多跳邻居,可以查询相互关联的信息,即使他们不在同一个文本块内部。
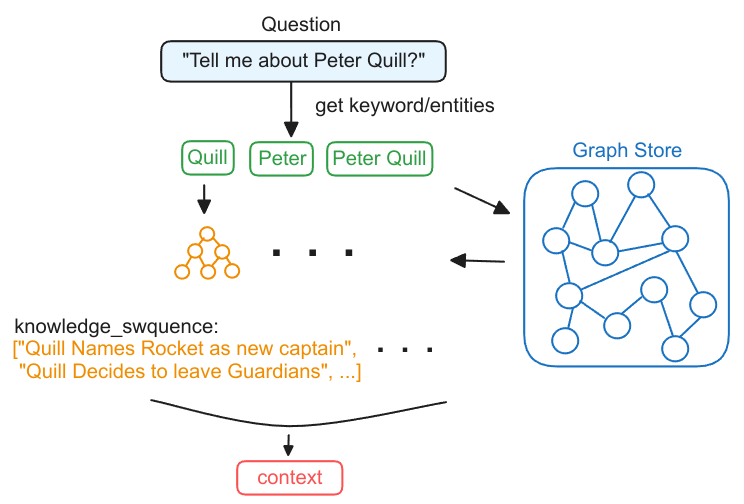
Graph RAG的执行过程可以简单概括为以下三步:
- 从问题中提取实体
- 从知识图谱中检索得到子图
- 根据子图构造上下文
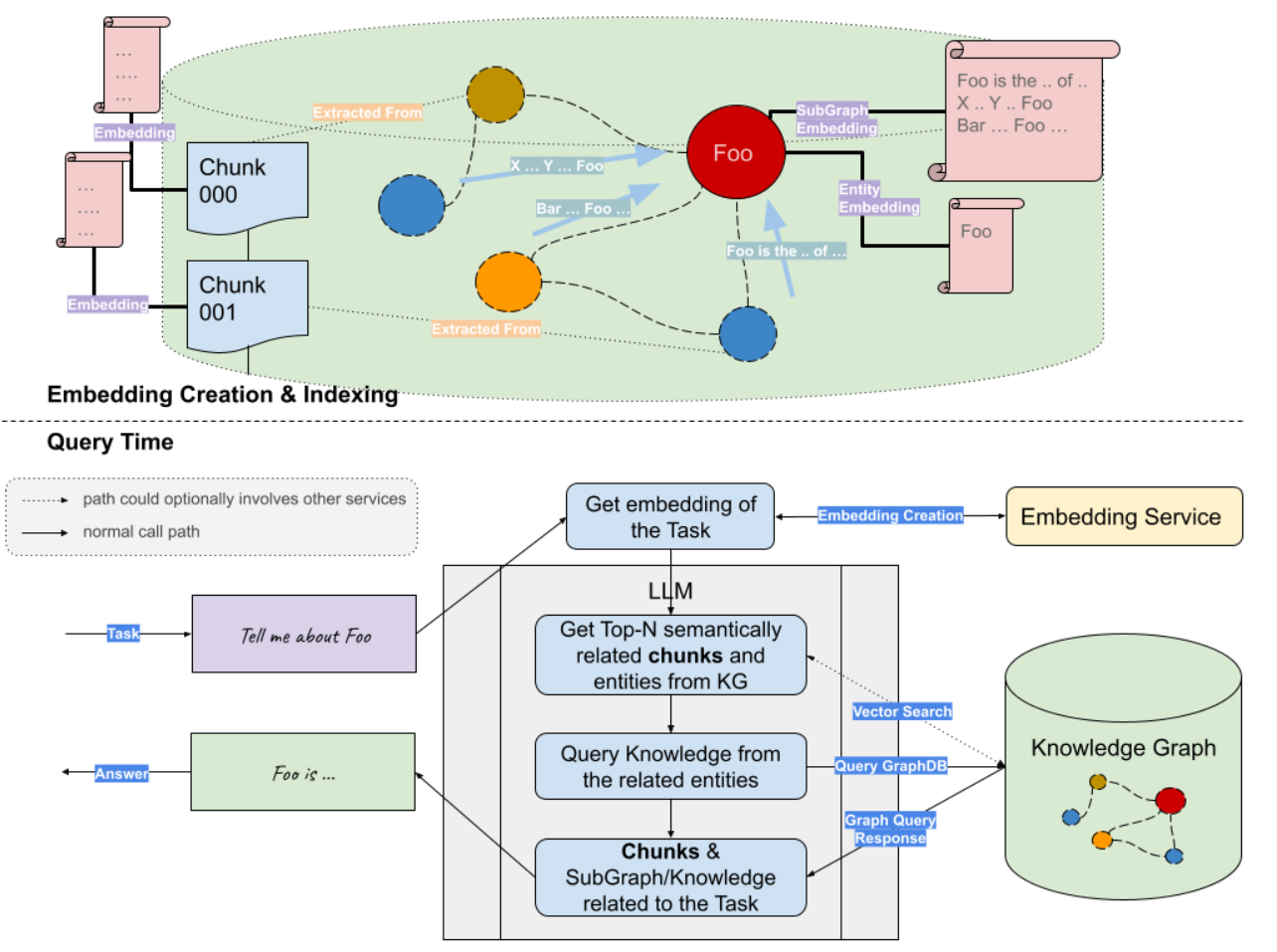
图3是Graph和Vector联合RAG的流程图。首先对外部的文档构建索引(向量索引和KG索引),用户后续的数据检索。当用户提交一个问题的查询时,首先通过嵌入模型对用户的问题生成向量表示,然后分别从向量数据库中检索语义相关的文本块;从知识图谱数据库中检索相关的实体,然后遍历得到实体相关的查询子图。最后将向量检索得到的文本块和知识图谱检索得到的查询子图,联合问题一起输入到LLM生成问题的回答。
Graph RAG可以看作是对已有方法的额外扩展。通过将知识图谱引入到RAG中,Graph RAG可以利用现有或者新建的知识图谱,提取细粒度,领域特定且相互关联的知识。
RAG Evaluate/Benchmark
RGB [AAAI 2024]
RGB是针对QA场景下的RAG benchmark工作,主要贡献如下:
- 构建了一个中英文的RAG benchmark。
- 从以下四个方面对RAG进行了评估,分析总结了LLM和RAG的局限性和缺点。
- Noise Robustness,表示LLM可以从噪声文档中提取有用的信息。其中噪声文档,是语文题相关但是不包含答案相关的信息。
- Negative Rejection,表示如果检索的文档不包含与答案相关的信息,LLM应该拒绝回答。
- information Integration,表示LMM是否可以回答需要整合多个文档信息的复杂问题。
- Counterfactual Robustness,表示当LLM通过prompt警告检索的信息可能包含事实错误的信息时,LLM可以识别文档中的事实错误。
数据集构造
QA instances generation,收集最新的新闻文章,然后使用ChatGPT对每个文章生成 (events, questions, and answers)。通过人工检查答案的正确性,并过滤掉一些无法从搜索引擎检索得到的数据。
Retrieve using search engine,对于每个问题,使用Google的API获取10个相关的网页,然后提取出相关的文档快。每个文档快包含300个token,使用
dense retrieval model(m3e-base,all-mpnet-base-v2) 选择top-30的文本块。这些文本被分为positive documents and negative documents。Testbeds construction for each ability
noise robustness,根据比例采样不同数量的negative documents。
negative rejection,只从negative documents中采样外部文档。
information integration,对问题进行expanding或者rewriting,使得问题的答案包含多个文档的信息。
例如:”Who won the MVP of Super Bowl 2023?” can be rewrite as “Who won the MVPs of Super Bowl 2022 and 2023?”
counterfactual robustness,利用LLM内部的知识生成问题的答案,然后检索出相关的文档,手动修改文档中的信息。
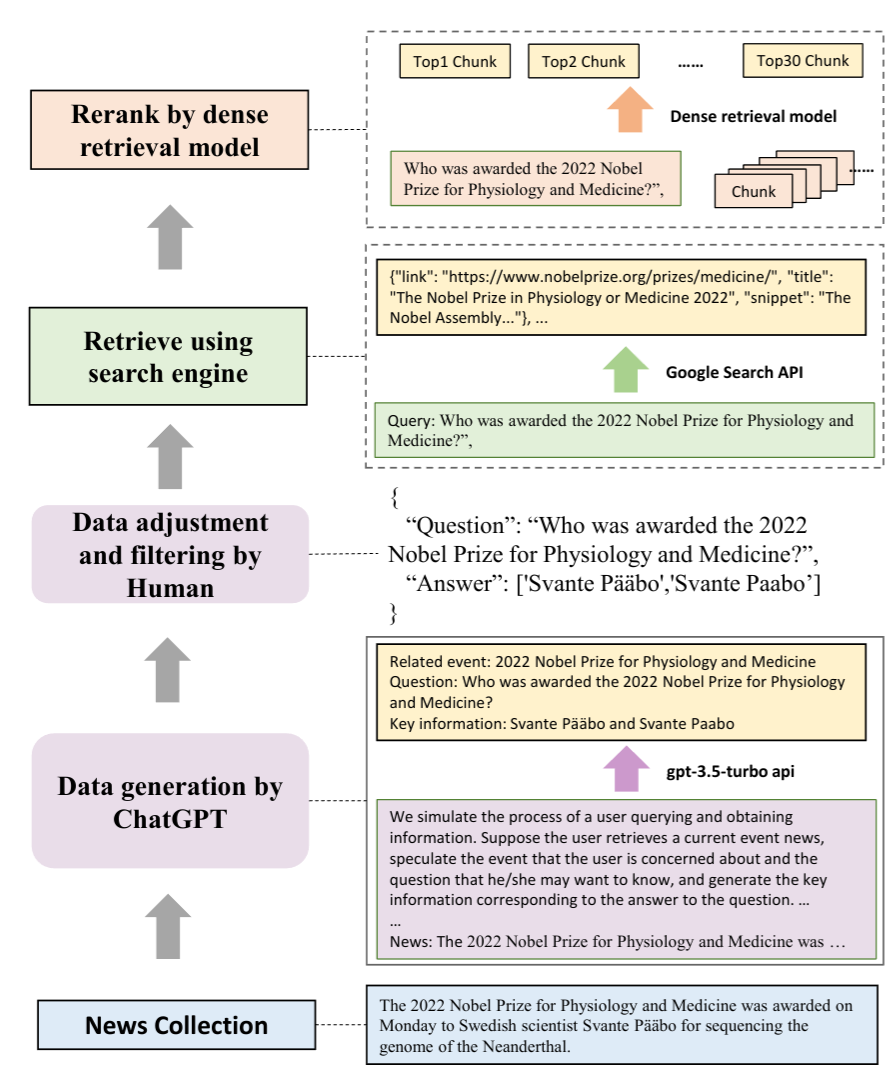
评估的metrics
- Accuracy ,用来评估noise robustness and information integration。生成的回答是否和标准答案一样。
- Rejection rate,评估negative rejection。当只提供negative documents,LLM应该输出”I can not answer the question because of the insufficient information in documents.”。
- Error detection rate,评估counterfactual robustness。当提供的文档包含错误的事实,LLM应该输出”There are factual errors in the provided documents.“。
- Error correction rate,评估LLM在识别出检索文档的事实错误后,是否可以回答出正确的答案。
实验结果
- RAG的性能随着噪声比例上升严重下降。存在以下问题:
- Long-distance information
- Evidence uncertainty
- Concept confusion.
- RAG很容易受到噪音信息的干扰,Negative Rejection很低。
- RAG在information integration上表现不佳,存在以下问提:
- Merging Error,成功识别了两个问题,但是在合并答案出错。
- Ignoring Error,没有正确识别两个问题,只回答了一个答案。
- Misalignment Error,两个问题的答案混淆。
- RAG基本没有识别事实错误的能力,因为这个RAG的基本假设冲突(模型缺乏信息,从外部检索相关信息),现有的LLM缺乏对错误信息的识别能力,严重依赖检索的信息。
参考文献
Retrieval-Augmented Generation for Large Language Models: A Survey
Graph_RAG_LlamaIndex_Workshop.ipynb
KG gets Fine-grained Segmentation of info. with the nature of interconnection/global-context-retained, it helps when retriving spread yet important knowledge pieces.
Hallucination due to w/ relationship in literal/common sense, but should not be connected in domain Knowledge
Custom Index combining KG Index and VectorStore Index
- Not all cases are advantageous, many other questions do not contain small-grained pieces of knowledges in chunks. In these cases, the extra Knowledge Graph retriever may not that helpful.
代码地址:github.com/Sanzo00/pi-car
树莓派配置:sanzo.top/RaspberryPi/raspi-setup

功能展示
远程控制小车

PWM变速
小车在低电压情况下跑的比较慢,因此增加变速的功能。

超声波自动避障
这里使用超声波测距模块(HC-SR04)实现距离检测,在此基础上实现一个简单的自动避障逻辑。

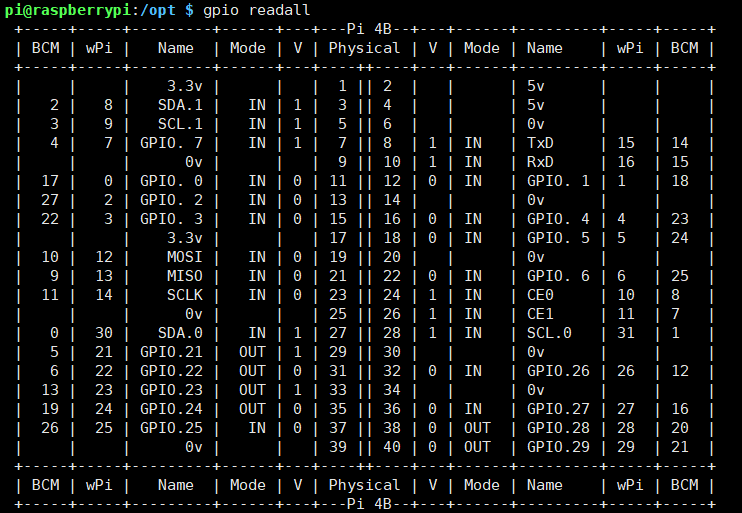
GPIO
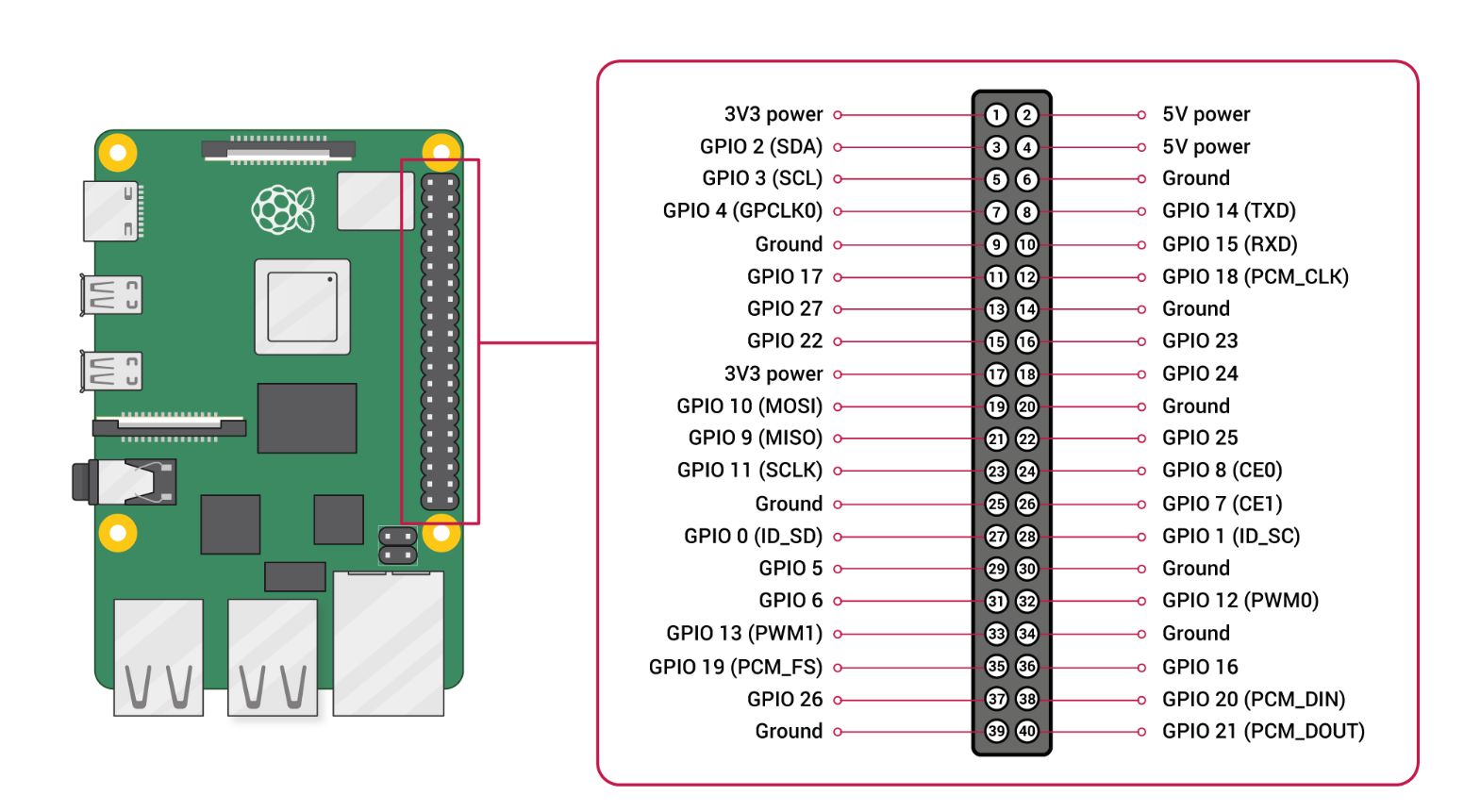
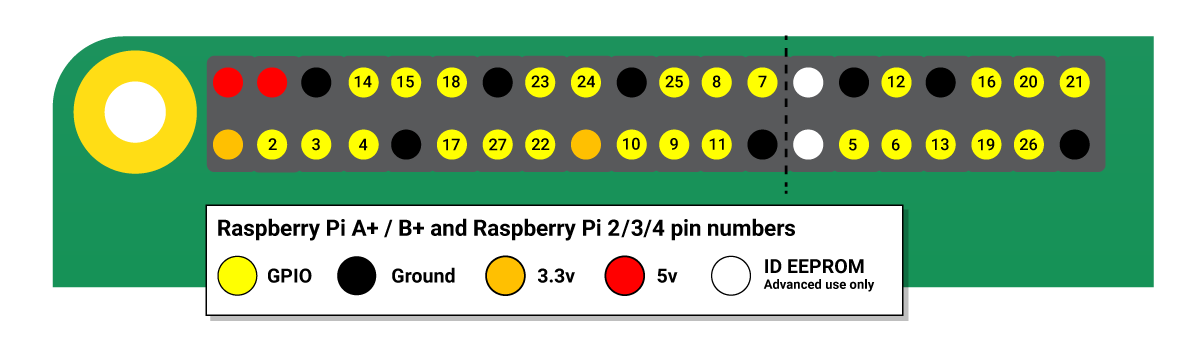
pinout
1 | sudo apt install python3-gpiozero |
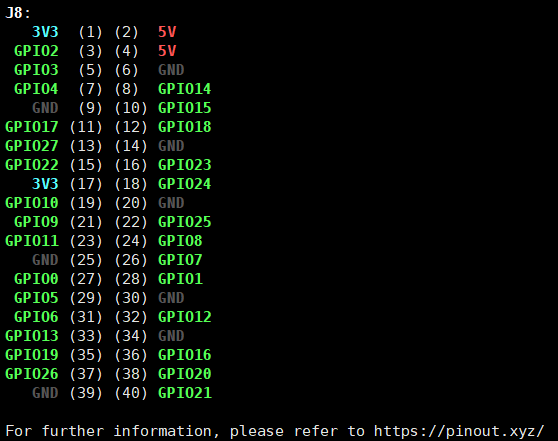
gpio readall
1 | wget https://project-downloads.drogon.net/wiringpi-latest.deb |
材料与安装
| 名称 | 数量 | 规格 |
|---|---|---|
| 树莓派4B | 1 | 4G |
| L298N电机驱动模块 | 1 | |
| 直流减速电机 | 4 | 工作电压:3-6V,减速比:1:48 |
| 神火18650 | 2 | 3.7V |
| 充电宝 | 1 | 5V3A |
| HC-SR04 | 1 | 2cm-400cm |
L298N
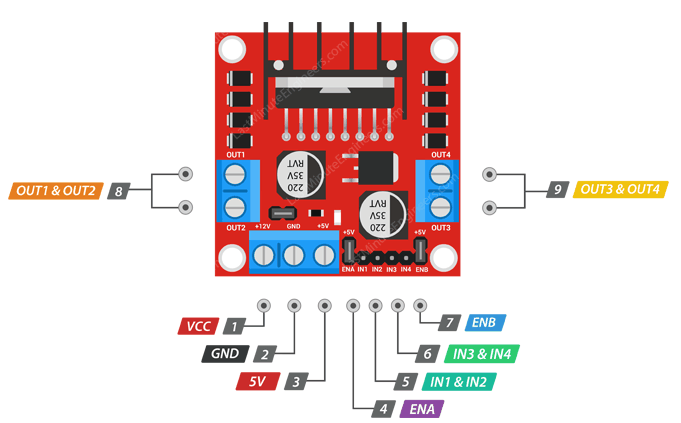
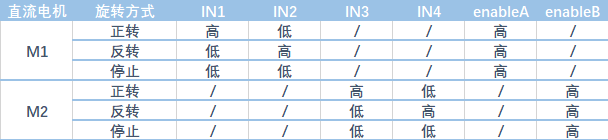
接线
这里使用树莓派的GPIO的BCM编号。
IN1、IN2、IN3、IN4分别接到树莓派的5、6、13、19上。
ENA、ENB接到树莓派的20、21。
HC-SR04

测距原理
将Trig置为高电平10us,HC-SR04发送8个40khz的方波,并检测是否有信号返回,此时Echo为高电平,若有信号返回,Echo自动置为低电平,Echo高电平持续的时间既是超声波从发射到返回的时间,最后利用声波公式计算距离$dis = \frac{time\space \times \space 340m/s}{2}$。
接线
VCC接树莓派或L298N的5V电源。
GND接树莓派GND。
Echo、Trig接树莓派GPIO 14、15。
电源
树莓派和L298N都单独供电,树莓派使用的是5V3A的充电宝供电,L298N使用电池盒供电。
电池盒的正极和负极,分别接到L298N的+12V、GND。
因为都是单独供电,所以将L298N的GND和树莓派的GND相互连接,这样方便同步逻辑信号。
HC-SR04使用树莓派的5V电源。
]]>镜像
Ubuntu:https://ubuntu.com/download/raspberry-pi
Pi OS:https://www.raspberrypi.com/software/operating-systems
balena:https://www.balena.io/etcher
更新源
1 | sudo vim /etc/apt/sources.list |
修改时区
Asia => Shanghai
1 | sudo dpkg-reconfigure tzdata |
vim配置
1 | set expandtab |
静态IP
sudo nano /etc/dhcpcd.conf
1 | interface eth0 |
sudo reboot
安装包
1 | sudo apt install -y lrzsz git proxychains libboost-all-dev samba samba-common aria2 cmake |
proxychains
1 | sudo vim /etc/proxychains.conf |
v2ray
脚本下载:
1 | # auto install |
安装包下载:
1 | unzip v2ray-linux-arm64-v8a.zip |
终端代理设置:
1 | export ALL_PROXY="socks5://127.0.0.1:7890" |
zsh
git
1 | # 设置账号信息 |
Docker
1 | # install |
support ipv6
1 | # start ipv6 nat |
打印机
docker安装
1 | # docker install |
手动安装
安装CUPS
1 | # 安装CUPS |

1 | # 重启服务 |
安装打印机驱动
1 | # 下载安装打印机驱动 |
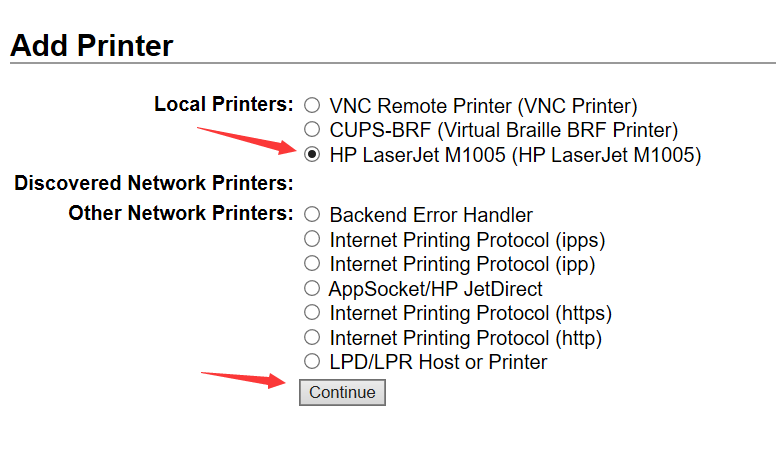
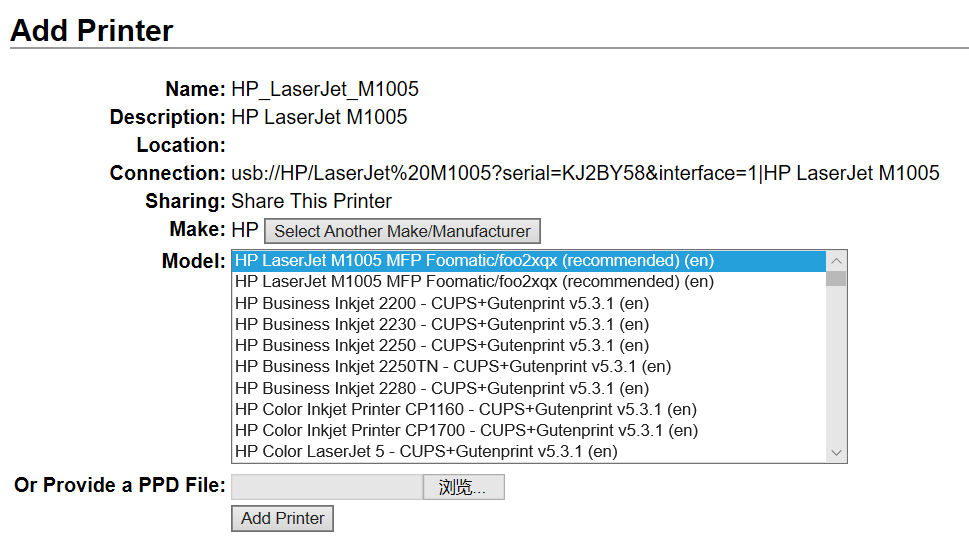
浏览器访问cups的配置页面http://192.168.31.240:631,添加对应的打印机。
记得要连接上打印机,而且要用root账号登录。

Windows添加打印机
https://192.168.31.240:631/printers/HP_LaserJet_M1005
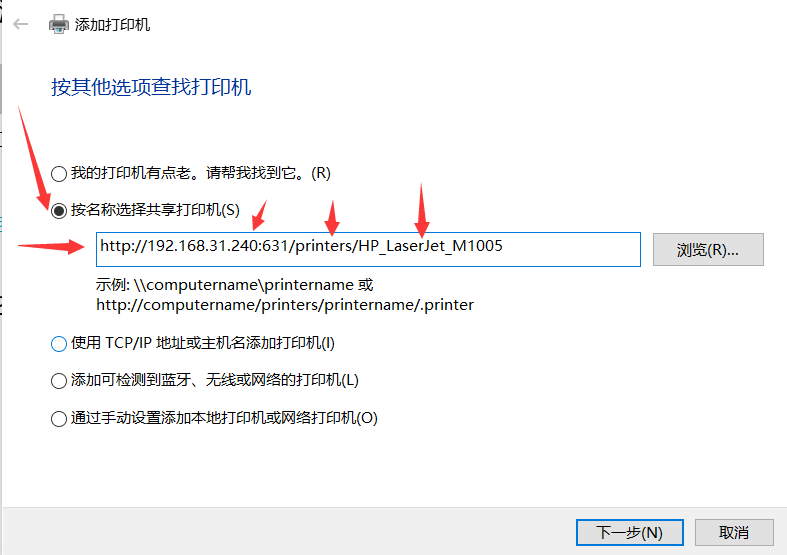
mac:https://support.apple.com/kb/DL1888?viewlocale=en_US&locale=en_US
挂载硬盘
1 | # 查看所用分区 |
Samba
1 | # 安装samba |
配置用户和密码
1 | # 创建密码文件 |
在我的电脑地址栏输入\192.168.31.240登录即可
清除windows下的net缓冲
1 | # 查看 |
若清除缓存后依然自动登录,则需要进入控制面板→用户账户→选择当前账户→管理你的凭据→Windows凭据→删除
qBittorrent
https://hub.docker.com/r/linuxserver/qbittorrent
1 | # download image |
在使用内网穿透访问局域网的qbittorrent服务时,需要取消勾选设置=>Web UI=>启动Host header属性验证。
WebDAV
1 | docker pull bytemark/webdav |
中文乱码
1 | docker exec -it webdav /bin/bash |
添加用户
1 | htdigest /user.passwd "WebDAV" user |
frp内网穿透
frps
1 | # configuration of frps |
1 | # install image |
frpc
1 | # configuration of frpc |
1 | # install image |
Aria2
海盗湾:https://thepiratebay.org/index.html
1337X:https://1337x.to/
LIMETORRENTS:https://www.limetorrents.pro/
TORLOCK:https://www.torlock.com/
ZOOQLE:https://zooqle.com/
YTS:https://yts.mx/
RARBG:https://rarbg.to/
使用容器
https://hub.docker.com/r/p3terx/aria2-pro
1 | mkdir aria2-pro && cd aria2-pro |
手动安装
1 | sudo apt install -y aria2 |
设置开机自启
1 | # 重新载入服务,并设置开机启动 |
AriaNg http://ariang.mayswind.net/latest
仪表盘
docker
1 | https://hub.docker.com/r/ecat/docker-pi-dashboard |
手动安装
安装软件包
1 | sudo apt-get install nginx php7.3-fpm php7.3-cli php7.3-curl php7.3-gd php7.3-cgi |
开启系统服务
1 | sudo service nginx restart |
浏览器访问http://树莓派ip
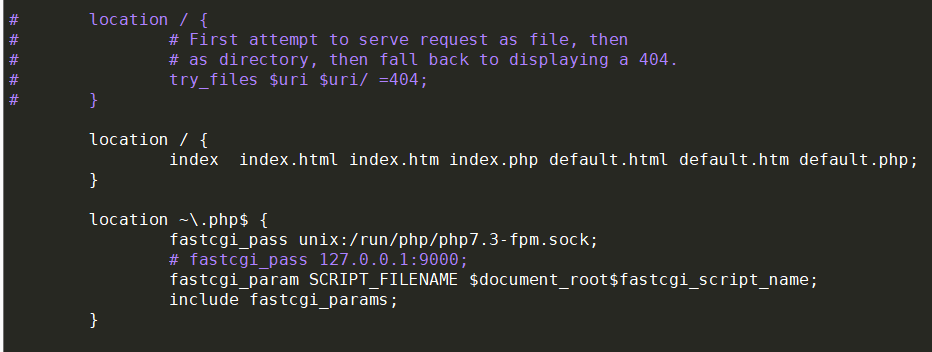
修改配置文件
sudo vim /etc/nginx/sites-available/default
1 | location / { |
替换为
1 | location / { |
重启服务sudo service nginx restart
部署项目
1 | sudo git clone https://github.com/nxez/pi-dashboard.git /var/www/html/pi-dashboard |
浏览器访问http://树莓派ip/pi-dashboard
VNC
开启VNC服务
1 | sudo raspi-config |
选择Interface Options => VNC,开启VNC服务。
下载VNC客户端
下载地址:realvnc
修改分辨率
如果VNC不能正常访问,可以通过修改树莓派分辨率解决。
1 | sudo raspi-config |
选择Display Options => Resolution => Mode4,接着重启机器即可。
]]>vim
1 | sudo apt install vim |
用户
1 | # 创建用户sanzo,指定home目录和登陆的shell |
代理
配置v2ray
1 | mkdir v2ray && cd v2ray |

proxychains
1 | sudo apt install proxychains |
apt代理
1 | sudo vim /etc/apt/apt.conf.d/proxy.conf |
bash代理
1 | vim ~/.bashrc |
在setting中设置了http,apt和bash应该可以不用再设置了,以防万一可以加上。
git
1 | sudo apt install git |
代理
1 | # http and https |
zsh
1 | # 安装zsh |
插件
1 | # 自动补全 |
鼠标
修改滑轮速度
1 | sudo apt install imwheel |
开机自启
1 | sudo ~/.config/systemd/user |
网速监控
1 | sudo add-apt-repository ppa:fossfreedom/indicator-sysmonitor -y |


截图
我在windows上用的snipaste,不过linux还没出,有两个方案可以代替:
1、系统默认的截图工具
PrtSc– 获取整个屏幕的截图并保存到 Pictures 目录。Shift + PrtSc– 获取屏幕的某个区域截图并保存到 Pictures 目录。Alt + PrtSc–获取当前窗口的截图并保存到 Pictures 目录。Ctrl + PrtSc– 获取整个屏幕的截图并存放到剪贴板。Shift + Ctrl + PrtSc– 获取屏幕的某个区域截图并存放到剪贴板。Ctrl + Alt + PrtSc– 获取当前窗口的 截图并存放到剪贴板。
1 | install |
显卡
Ubuntu20.04安装NVIDIA显卡驱动+cuda+cudnn配置深度学习环境
驱动安装
1 | 查看显卡型号 |


1 | sudo apt install -y lightdm gcc make |
1 | 测试是否成功 |

如果出现/dev/xxx: clean的问题,进不了桌面,可能是因为驱动不匹配的问题。可以删除/etc/X11/xorg.conf。
如果出现An NVIDIA kernel module 'nvidia-drm' appears to already be loaded in your kernel. This may be because it is in use (for example, by an X server, a CUDA program, or the NVIDIA Persistence Daemon), but this may also happen if your kernel was configured without support for module unloading.
1 | # https://unix.stackexchange.com/questions/440840/how-to-unload-kernel-module-nvidia-drm |
安装cuda
下载cuda,这里我选择的是cuda 11.2。

1 | wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run |
回车取消勾选Driver,因为前面已经装过驱动,然后install,也可以在Options中自定义安装位置。

在.bashrc文件中配置环境变量
1 | export PATH=/usr/local/cuda-11.2/bin:${PATH} |
1 | source ~/.bashrc |

安装cudnn
1 | 将文件复制到cuda对应的文件夹下 |
测试
在~/NVIDIA_CUDA-11.2_Samples下编译代码,然后运行cuda提供的例子。


踩坑
apt 更新软件包之后,导致显卡驱动失效,这是因为内核版本发生了变化,将内核回退到上一个版本即可。
显示器
适用于多个显示器。
我这里有两块屏幕HDMI-1,HDMI-1-0。
1 | 查看当前显示器信息 |
开机自启
还没找到合适的开机自启命令,不过可以在系统设置中调。
VSCode
server端网络不好,“Downloading VS Code Server”
进入~/.vscode-server/bin/查看vscode server的commit id,然后手动下载上传到服务器。
下载链接:https://update.code.visualstudio.com/commit:${commit_id}/server-linux-x64/stable
解压之后重命名为commit id,然后放到~/.vscode-server/bin/
其他
]]>setup
1 | # install yabai |
command
| Function | Shortcuts |
|---|---|
| Focus within space | Alt + (H, J, K, L) |
| Focus between display | Alt + (W, E) |
| Toggle window float | Shift + Alt + F |
| Maximize window | Alt + M |
| Balance layout | Alt + B |
| Swap window | Shift + Alt + (H, J, K, L) |
下载安装
1 | 安装zsh |
离线安装:
https://www.jianshu.com/p/c65f145772c2
https://github.com/ohmyzsh/ohmyzsh/wiki/Installing-ZSH
1 | # install zsh |
按键映射
1 | 编辑.zshrc文件,添加如下配置 |
插件
1 | 自动补全 |
代理
1 | # 打开配置文件 |